- [Parallel Monitor API: New processor tiers, snapshots and event streams, and Basis on every event](https://parallel.ai/blog/monitor-api-ga)
Tags:Product Release
Reading time: 7 min
Today, we’re announcing major upgrades to the quality and capabilities of our Search and Extract APIs, and making both generally available. These enhancements deliver industry-leading accuracy and token efficiency for web search across diverse use cases, including company research, coding agents, multilingual queries, finance, and broad internet research.
As AI agents have become better at handling knowledge work that needs the web, two main product patterns have emerged: interactive workflows and long-running background tasks.
Interactive workflows support real-time collaboration between a user and an agent. They are shaped by latency requirements and frequently focus on targeted web research or fetching specific information.
Background tasks work more independently on ambiguous, multi-step questions spanning several topics. These searches typically require deeper retrieval and orchestration of multiple tool calls.
The Search API now offers two modes designed for these distinct use cases.
**Basic mode** is optimized for quick retrieval. It delivers P50 latency under one second and P90 under two seconds, making it a good fit for interactive, human-in-the-loop experiences.
**Advanced mode** is built for depth and cost efficiency. It spends more time querying, reranking, and compressing results across both general-purpose and specialized indexes. Traditional search APIs often force agents into a series of sequential searches that expand the context window, increasing latency and inflating cost. Advanced mode resolves more in a single call, with lower end-to-end agent cost.
| Search Mode | Median Latency (P50) | Best for |
|---|---|---|
| Basic | 1s | Single-hop, latency-sensitive agents, e.g., human-in-loop chat, interactive experiences |
| Advanced | 3s | Multi-hop background agents that can tolerate extra latency for better depth and cost-efficiency, e.g., code review agents, deep research |
COST (CPM)
ACCURACY (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
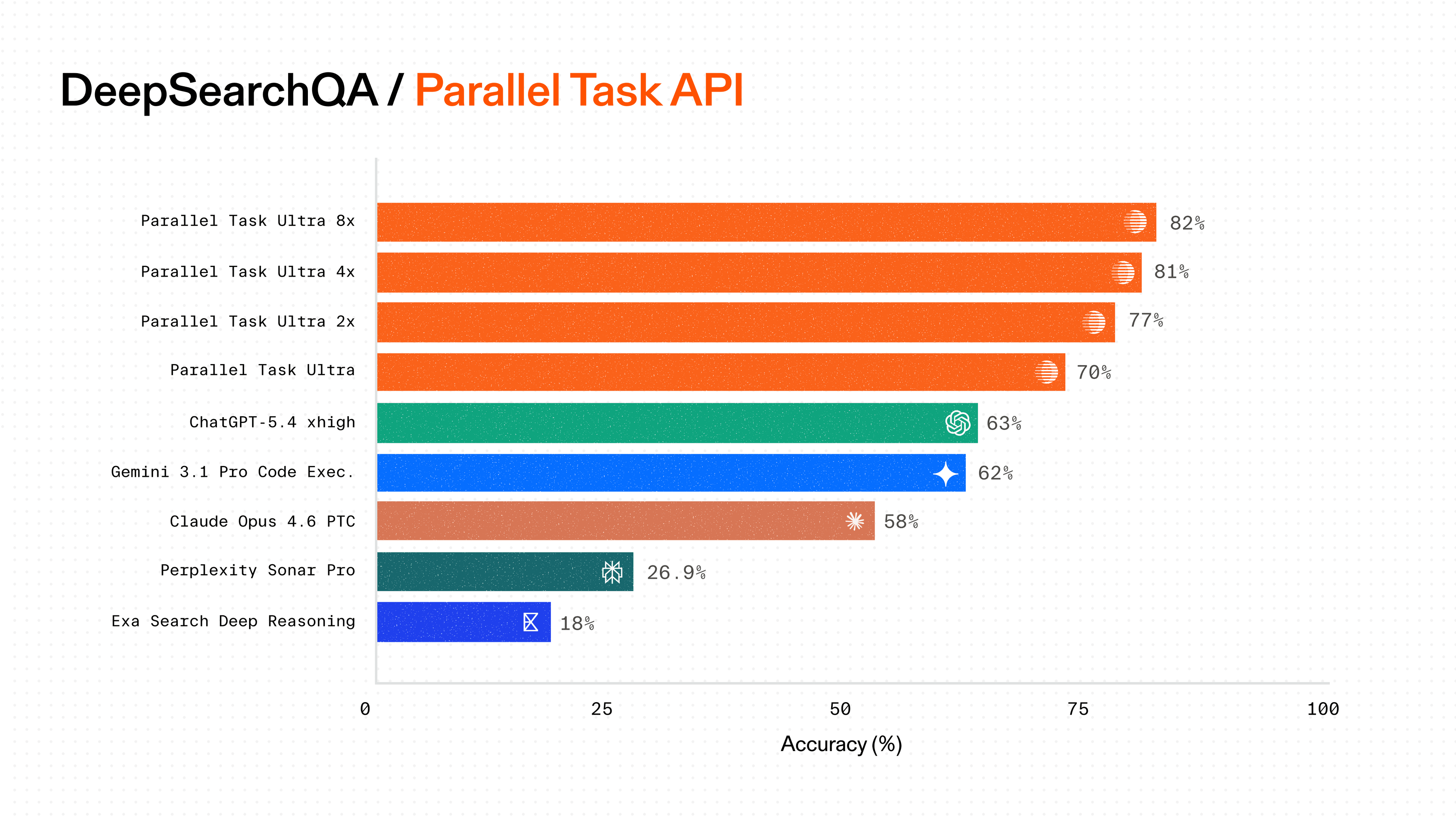
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Others | Tavily | 973 | 42 | | Others | Exa | 1160 | 40 | | Parallel | Parallel Basic | 600 | 53 | | Parallel | Parallel Advanced | 379 | 51 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Parallel | Parallel Basic | 451 | 58 | | Parallel | Parallel Advanced | 315 | 56 | | Others | Exa | 522 | 57 | | Others | Tavily | 538 | 54 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Parallel | Parallel Basic | 258 | 45 | | Parallel | Parallel Advanced | 191 | 41 | | Others | Tavily | 243 | 45 | | Others | Exa | 326 | 41 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to MAX_TOOL_CALLS=25 tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Others | Exa | 210 | 74 | | Others | Tavily | 202 | 71 | | Parallel | Parallel Advanced | 101 | 73 | | Parallel | Parallel Basic | 155 | 71 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Parallel | Parallel Advanced | 49 | 79 | | Parallel | Parallel Basic | 90 | 77 | | Others | Exa | 84 | 78 | | Others | Tavily | 89 | 78 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Parallel | Parallel Advanced | 93 | 87 | | Parallel | Parallel Basic | 165 | 84 | | Others | Exa | 169 | 87 | | Others | Tavily | 189 | 83 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
We evaluated search providers against five open benchmarks covering complementary aspects of agentic search: BrowseComp (hard multi-hop questions that require navigating the live web), Frames (multi-document factoid reasoning), FreshQA (time-sensitive questions where the correct answer depends on recent web information), HLE (Humanity's Last Exam — expert-level academic questions spanning math, science, and humanities), SealQA (ambiguity-robust factoid QA with intentionally misleading snippets), WebWalker (tasks designed around following links across pages to find an answer).
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
We believe the best web search API for agents is a strong general-purpose system with the scale, depth, and ranking quality to perform well across many kinds of knowledge work.
Our API is built on that foundation. It offers broad coverage of the web while going deep in the domains that matter most, so agents can retrieve high-quality results for both general research and specialized tasks. Whether the job is debugging against current library documentation or researching a prospect’s funding history and tech stack, the same strengths apply: a large index, deep retrieval, and strong ranking.
Advanced mode is designed for the most demanding workflows, where agents benefit from deeper retrieval and more precise ranking across both broad web content and domain-relevant sources.
On our internal dataset focused on company search, Parallel’s Search API outperforms alternatives in finding highly relevant candidates that meet the specified search criteria.

Similarly, for queries generated by coding agents as part of development workflows, Parallel’s Search API provides the most relevant code snippets and documents.
COST (CPM)
ACCURACY (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
A proprietary coding dataset derived from production queries to Parallel’s search API.
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report the accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ----------------- | ---------- | ------------ | | Parallel | Parallel Advanced | 154 | 82 | | Parallel | Parallel Basic | 269 | 81 | | Others | Exa | 331 | 80 | | Others | Tavily | 352 | 75 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
**Dataset**
A proprietary coding dataset derived from production queries to Parallel’s search API.
**Evaluation methodology**
Every task is run through a shared deep-research harness: a single GPT-5.4 agent is given two tools (web search and web fetch) with an iterative budget of up to `MAX_TOOL_CALLS=25` tool calls per question. The agent plans sub-queries, fans out searches, fetches specific pages when snippets are insufficient, and returns an answer when it exhausts the number of allowed tool calls or has sufficient information to answer the question. Each answer is then LLM-graded by GPT-5.4. We report the accuracy of the final answer.
We measure accuracy and overall cost, which includes LLM token costs and tool call costs.
**Testing dates**
April 19-21, 2026
Search and Extract are designed to work together. Search finds the right sources with high precision. Extract turns those sources into concise, task-relevant context that an agent can use efficiently.
The Parallel Extract API is especially useful when the source is long or dense, such as a 200-page SEC filing, an investor document, or a complex technical page. Passing the full source into context increases token usage and makes downstream reasoning less focused.
The Parallel Extract API solves this by letting the agent specify an extraction objective. After Search identifies the right source, Extract returns only the content most relevant to that objective. The result is a more efficient retrieval pipeline: Search provides breadth and precision, while Extract compresses large pages and documents into high-signal context for the next reasoning step.
Together, they give agents the best of both: high-quality retrieval and high-quality compression in a single workflow.
On FinanceBench[FinanceBench](https://docs.patronus.ai/docs/research_and_differentiators/financebench), built around real-world workflows across SEC filings, earnings reports, and multi-page investor documents, the extract API consistently succeeds at getting the highest recall for any number of tokens returned.

Sophisticated AI products serve users globally. A GTM agent may prospect across markets, a compliance agent may track filings across jurisdictions, and a research assistant may serve users in many languages. These workflows require a search layer that can retrieve fresh, relevant content across languages and regions with consistent quality.
The Parallel Search API now supports this natively, giving agents a stronger foundation for global workflows.

Parallel builds web infrastructure for AI. We give AI agents structured, grounded access to the open web, enabling agents to find, extract, monitor, and reason over information at a scale and quality no human workflow can match. Our infrastructure is powered by a rapidly growing proprietary index of the global internet, built from the ground up for AI consumption.
Fortune 100s and leading frontier AI companies, including Harvey, Manus, Modal, Starbridge, and Profound, rely on Parallel for grounding, fact-checking, contract monitoring, and high-quality content generation.
Get started on our Developer Platform[Developer Platform](https://platform.parallel.ai/) or read the documentation[documentation](https://docs.parallel.ai/).
By Parallel
April 21, 2026