Jul 20, 2026
- [Building a vendor intelligence system with Parallel](https://parallel.ai/blog/vendor-intelligence-system)
Tags:Developers
Author: By Sahith JagarlamudiNovember 18, 2025
Parallel's new FindAll API turns natural language queries into custom datasets from the web. It finds entities like companies, people, or locations based on your criteria, then enriches them with structured data—all with citations. FindAll Pro achieves 61% recall, 3x better than competitors.

Today, we're announcing the newest product in our suite of **Web Agent APIs**: the **FindAll API**.
**FindAll** is the best way to create your own custom database from the web, with just a simple natural language query. It’s available now to try in the Parallel Developer Platform[Developer Platform].
**FindAll** finds any set of entities (companies, people, events, locations, houses, etc.) based on a set of match criteria. For example, with **FindAll, **you can run a natural language query like “Find all dental practices located in Ohio that have 4+ star Google reviews.”

This is a powerful way to discover the complete long tail of interesting entities from the web and filter them down with match criteria that are personalized to your unique use case. The result is an extensible tool that can produce high-quality datasets on demand, as opposed to buying static, stale, and generic datasets.
FindAll executes a three-stage pipeline optimized for both coverage and efficiency:
**1. Generate candidates from web data: FindAll** searches across our proprietary web index to identify potential entities matching your query. Unlike traditional search, which returns a fixed result set, **FindAll** generates candidates dynamically based on your specific criteria.
**2. Evaluate against match conditions: **Each candidate is evaluated against your match conditions using multi-hop reasoning across web sources. Only candidates which satisfy all conditions reach matched status and are included in the results. This staged approach means you only pay to process entities that actually matter.
**3. Extract Structured Enrichments: **For matched entities, **FindAll** automatically orchestrates our **Task API**[**Task API**] to extract any additional fields you've specified— from basic attributes like revenue and employee count to complex data points like the strategic initiatives a company is prioritizing.

Every data point returned includes comprehensive verification through our **Basis framework**[**Basis framework**]— citations linking to source materials, detailed reasoning for match decisions, relevant excerpts from web pages, and calibrated confidence scores. This granular attribution enables human-in-the-loop workflows for verifiability and provenance.
To test the performance of **FindAll**, we created our own benchmark of 40 complex multi-criteria queries covering public companies, startups, SMBs, specialized entities, and people (e.g., executives, researchers, and professionals). Recall measures the proportion of all correct matches within the entire competitive set of successfully identified entities.
Some sample questions:
****
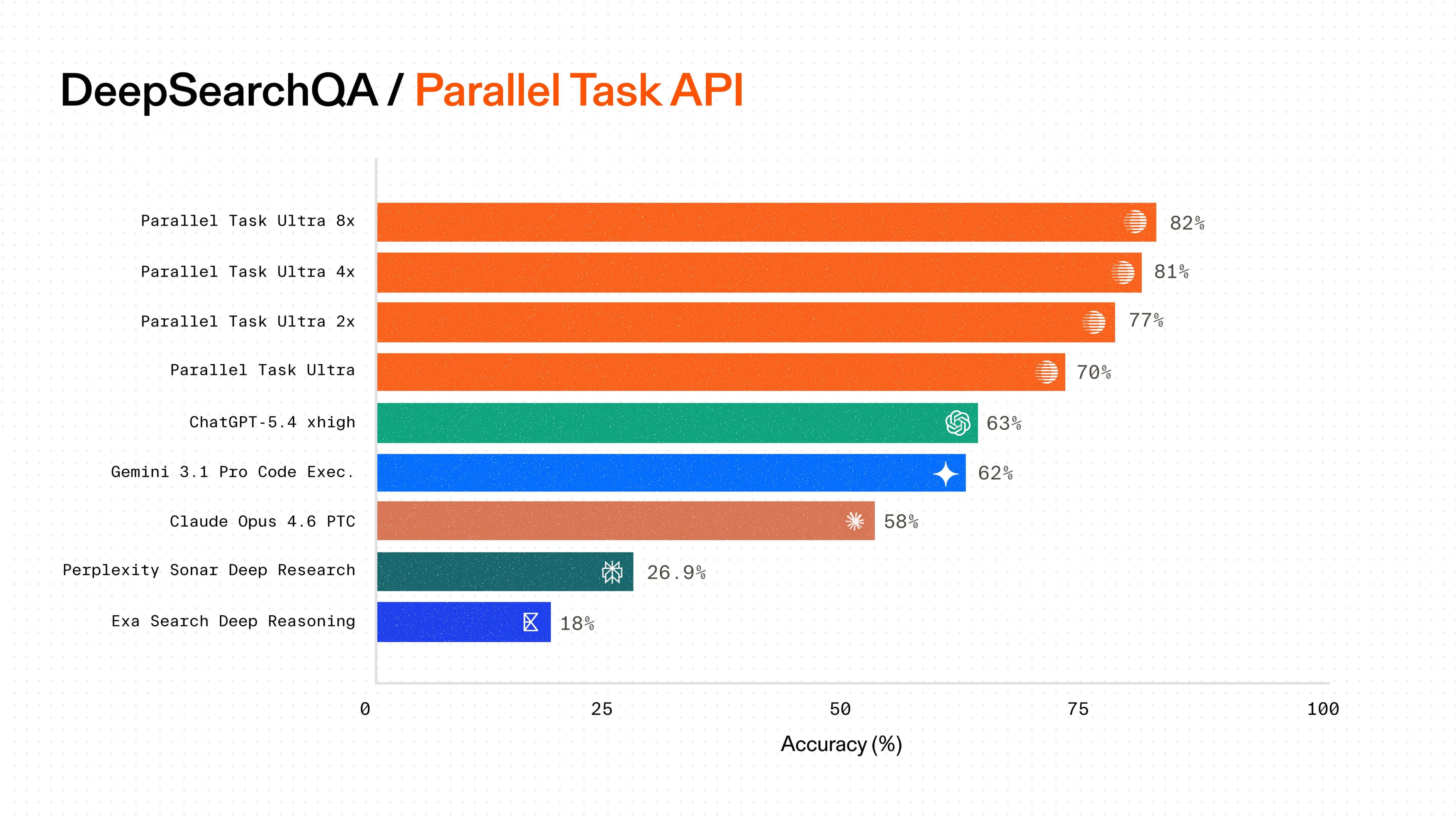
**FindAll Pro** achieves state-of-the-art results with 61% recall, ~3X higher than OpenAI Deep Research, Anthropic Deep Research, and Exa. Higher recall means that Parallel **FindAll **finds more correct matches for a given query.** FindAll** **Base** also achieves 30% recall while being the lowest cost on the market, making it the most cost-effective yet performant option.
Recall (%)
COST (CPM)
RECALL (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark, created by Parallel, contains 40 complex multi-criteria queries covering public companies, startups, SMBs, specialized entities, and people (e.g., executives, researchers, professionals).
To measure recall we take the number of correct matches / total entities in the ground truth dataset. The ground truth dataset is created by taking the union of all correct matches across the competitor set. Cost is calculated as the average cost to find 1000 correct matches.
Nov 13th-17th, 2025
This benchmark, created by Parallel, contains 40 complex multi-criteria queries covering public companies, startups, SMBs, specialized entities, and people (e.g., executives, researchers, professionals).
To measure recall we take the number of correct matches / total entities in the ground truth dataset. The ground truth dataset is created by taking the union of all correct matches across the competitor set. Cost is calculated as the average cost to find 1000 correct matches.
Nov 13th-17th, 2025
| Series | Model | Cost (CPM) | Recall (%) | | -------- | ----------------------- | ---------- | ---------- | | Parallel | FindAll Base | 60 | 30.3 | | Parallel | FindAll Core | 230 | 52.5 | | Parallel | FindAll Pro | 1430 | 61.3 | | Others | OpenAI Deep Research | 250 | 21 | | Others | Anthropic Deep Research | 1000 | 15.3 | | Others | Exa | 110 | 19.2 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark, created by Parallel, contains 40 complex multi-criteria queries covering public companies, startups, SMBs, specialized entities, and people (e.g., executives, researchers, professionals).
To measure recall we take the number of correct matches / total entities in the ground truth dataset. The ground truth dataset is created by taking the union of all correct matches across the competitor set. Cost is calculated as the average cost to find 1000 correct matches.
Nov 13th-17th, 2025
The **FindAll** API is available today. Get started with our Developer Platform[Developer Platform] or dive into the documentation[documentation].
123456789101112131415161718192021222324import requests
url = "https://api.parallel.ai/v1beta/findall/runs"
payload = {
"objective": "<string>",
"entity_type": "<string>",
"match_conditions": [
{
"name": "<string>",
"description": "Company must have SOC2 Type II certification (not Type I). Look for evidence in: trust centers, security/compliance pages, audit reports, or press releases specifically mentioning 'SOC2 Type II'. If no explicit SOC2 Type II mention is found, consider requirement not satisfied."
}
],
"generator": "base",
"match_limit": 123
}
headers = {
"x-api-key": "<api-key>",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())``` import requests url = "https://api.parallel.ai/v1beta/findall/runs" payload = { "objective": "<string>", "entity_type": "<string>", "match_conditions": [ { "name": "<string>", "description": "Company must have SOC2 Type II certification (not Type I). Look for evidence in: trust centers, security/compliance pages, audit reports, or press releases specifically mentioning 'SOC2 Type II'. If no explicit SOC2 Type II mention is found, consider requirement not satisfied." } ], "generator": "base", "match_limit": 123}headers = { "x-api-key": "<api-key>", "Content-Type": "application/json"} response = requests.post(url, json=payload, headers=headers) print(response.json())``` Parallel develops critical web search infrastructure for AI. Our suite of web search and agent APIs is built on a rapidly growing proprietary index of the global internet. These solutions transform human tasks that previously took days and weeks into agentic tasks that now take seconds and minutes.
Fortune 100 and 500 companies use Parallel’s web intelligence APIs in insurance, finance, and retail, as well as AI-first businesses like Clay, Starbridge, and Sourcegraph.
Sign up for free. No credit card required.
By Parallel
November 18, 2025