Jul 16, 2026
- [Parallel and Google Cloud Announce Partnership for Agentic Web Search on Gemini Enterprise Agent Platform](https://parallel.ai/blog/google-cloud-partnership)
Tags:Product
Author: By ParallelFebruary 23, 2026
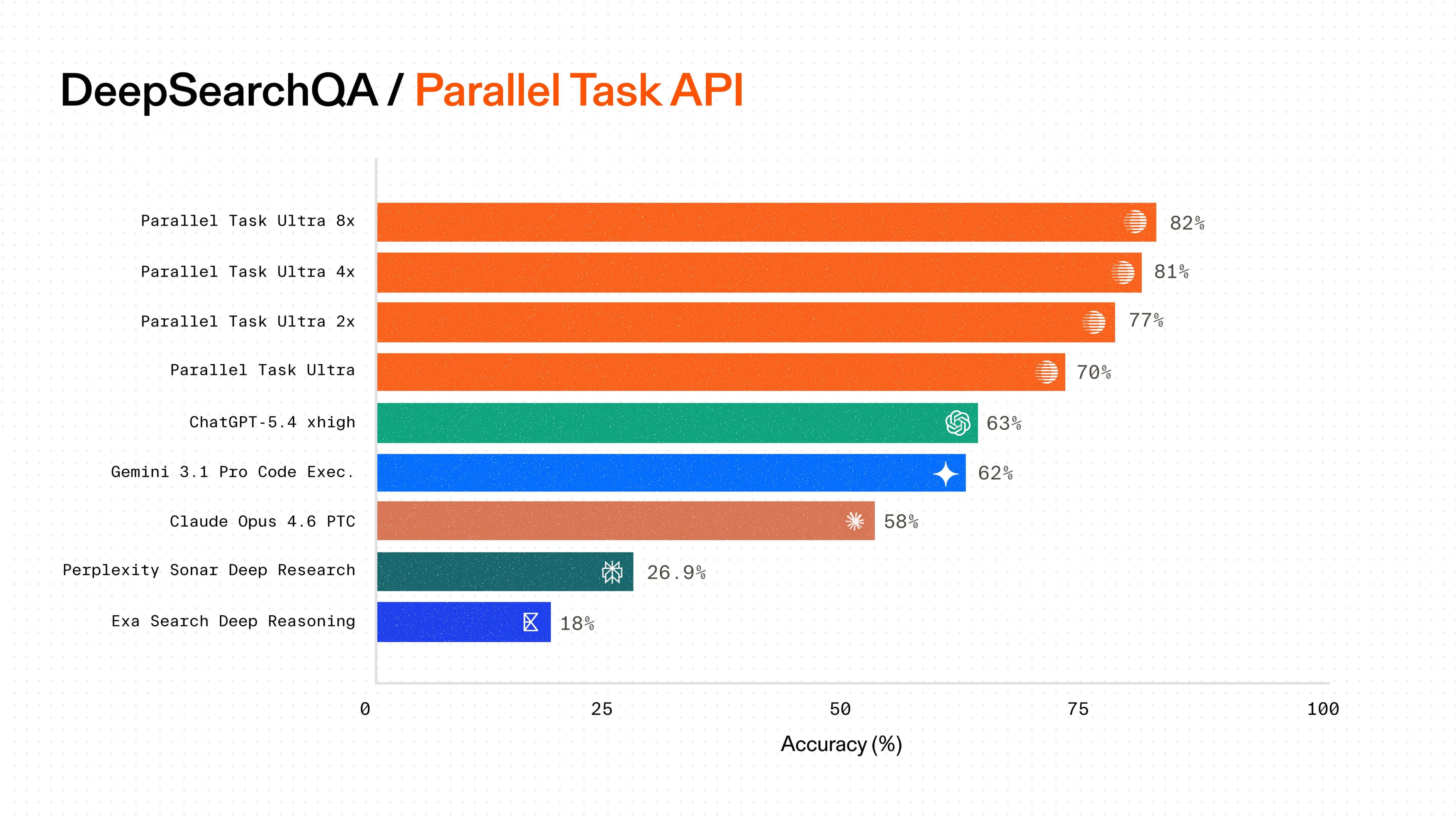
Tabstack, Mozilla's browsing infrastructure for AI agents, integrated Parallel's Search API to give its /automate and /research endpoints the ability to discover the right pages before navigating them, combining Parallel's search accuracy with Tabstack's browser execution at scale.

Tabstack is Mozilla's web execution layer for AI agents. It provides a developer API that enables AI systems to browse, search, and interact with the web autonomously, handling the full complexity of headless browser orchestration, JavaScript rendering, and adaptive page interaction so developers can focus on building agent logic instead of managing browser infrastructure.
Tabstack is built by Mozilla, the nonprofit-backed organization behind Firefox and one of the longest-standing advocates for an open, accessible internet. With Tabstack, Mozilla is extending that mission into the age of AI agents, building browsing infrastructure that prioritizes privacy, data minimization, and publisher respect as the web's primary users shift from humans to machines.
As a member of the Mozilla family, Tabstack's core strength is web browsing. Once an agent knows where to go, Tabstack handles the clicking, scrolling, form-filling, and data extraction with production-grade reliability. But for its /automate and /research endpoints, there's a critical step before any browser session begins: the agent needs to figure out which pages to visit.
This is especially important for the /research endpoint, which runs a multi-phase agentic loop, decomposing complex questions into sub-queries, executing parallel searches, evaluating gaps in the collected data, and recursively searching again until it reaches sufficient coverage. The quality of the initial search results directly determines the efficiency of the entire loop. Poor search results mean more wasted browser sessions, more token spend on irrelevant pages, and longer time-to-answer.
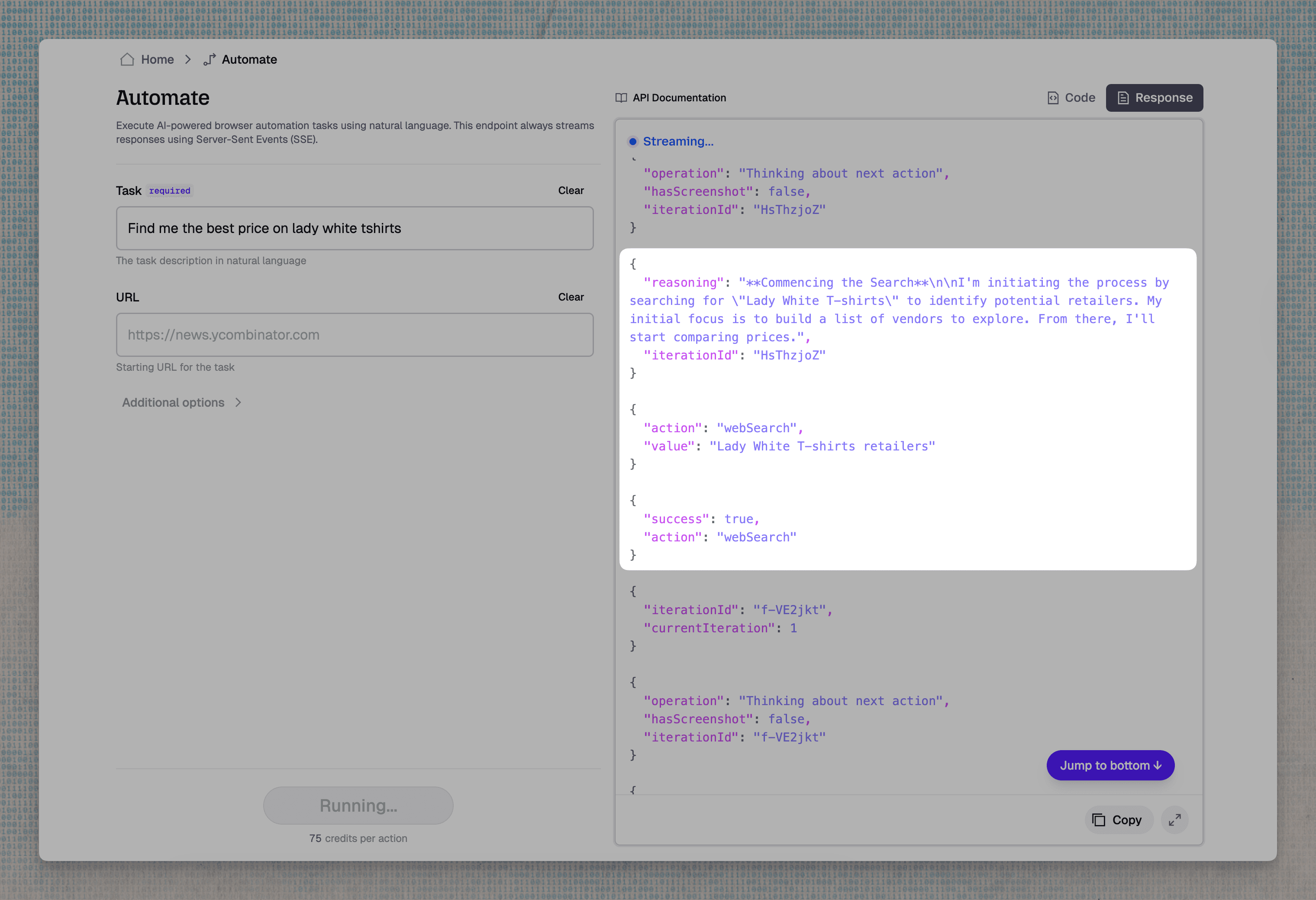
For the /automate endpoint, the challenge is similar but more immediate. When an agent receives a natural language task like "find the pricing page for this SaaS product and extract the enterprise tier details," it needs to locate the right starting URL before it can begin navigating. Generic search results, the kind optimized for human clicks rather than agent workflows, often point to blog posts, comparison sites, or outdated cached pages instead of the authoritative source.
Tabstack needed a search layer that was purpose-built for AI agents: one that prioritizes authoritative, fresh results over engagement-optimized rankings, and that returns content formatted for machine consumption rather than human browsing.
> _As we began building Tabstack, we recognized early on that agent native search was a critical component of our automation layer. Most providers we evaluated were still optimizing for human browsing, which often creates friction for agent workflows. Parallel stood out for its ability to consistently surface authoritative, up-to-date information in clean, structured formats that integrate smoothly into our agentic loop. _
> _— Jacob Ervin, Product Lead, Tabstack_
Parallel's Search API is built natively for agents. Rather than returning ranked links optimized for click-through, it identifies the optimal context from the web to help an agent reason, delivering results with relevant extracts, source metadata, and structured outputs designed for downstream machine processing.
**Search-powered browser automation (/automate)**: When a user sends a natural language task to Tabstack's /automate endpoint, Parallel's Search API handles the initial discovery, identifying the most relevant URLs for the agent to visit before Tabstack's browsing layer begins clicking, scrolling, and interacting. This means the agent starts each browser session on the right page, rather than wasting compute navigating from generic search results.
**Recursive research with high-quality search inputs (/research)**: Tabstack's /research endpoint runs a multi-pass agentic loop: planning, parallel execution, gap evaluation, and verification. Parallel's Search API powers the search queries at each phase of this loop, from the initial fan-out of sub-queries to the targeted follow-up searches triggered when the system detects gaps or conflicting data. Better initial search results mean fewer recursive passes, lower token spend, and faster time-to-answer.
**Authoritative source prioritization**: Parallel's search infrastructure is tuned for accuracy over engagement. For Tabstack's research agents, this means queries surface official documentation, primary sources, and authoritative pages—not the SEO-optimized blog posts and outdated comparison articles that typically dominate consumer search rankings. This is particularly valuable for complex research tasks like regulatory comparisons or enterprise due diligence, where the difference between an authoritative source and a marketing page can change the conclusion entirely.
The Parallel + Tabstack integration represents a natural separation of concerns in the emerging web infrastructure stack for AI agents. Parallel excels at searching and reasoning over the open web, finding the right information across billions of pages. Tabstack excels at executing on the web, navigating, interacting, and extracting data from the pages that Parallel identifies.
Together, they create a complete search-to-action pipeline. Parallel handles the "what" and "where." Tabstack handles the "how."
> _“Web browsing and search have historically been tightly coupled systems. By integrating Parallel web search directly into Tabstack’s API, we’ve reduced the coordination overhead and created a more cohesive developer experience. Our customers benefit from the simplified architecture, which leads to more consistent inputs, fewer edge cases, and more reliable downstream behavior in production.”_
Sign up for free. No credit card required.
By Parallel
February 23, 2026