Jul 13, 2026
- [Introducing Parallel Search Turbo](https://parallel.ai/blog/parallel-search-turbo)
Author: By Parallel
September 12, 2025
Build a competitive intelligence platform with the Parallel Task API configured with Reddit MCP tool calls.

We built a full-stack competitive intelligence platform by combining data from Reddit and the public web.
View the complete app here[here](https://competitive-analysis-demo.parallel.ai/).

The app we built allows users to:
Technology stack:
Get started in 5 minutes:
123git clone https://github.com/your-username/competitive-analysis-demo
cd competitive-analysis-demo
npm install``` git clone https://github.com/your-username/competitive-analysis-demo cd competitive-analysis-demo npm install``` 1234567891011121314151617181920212223{
"$schema": "https://unpkg.com/wrangler@latest/config-schema.json",
"name": "competitor-analysis",
"main": "worker.ts",
"compatibility_date": "2025-08-14",
"assets": { "directory": "./public" },
"observability": { "logs": { "enabled": true } },
"durable_objects": {
"bindings": [
{ "name": "COMPETITOR_ANALYSIS", "class_name": "CompetitorAnalysisDO" }
]
},
"migrations": [
{ "tag": "v1", "new_sqlite_classes": ["CompetitorAnalysisDO"] }
],
"routes": [
{
"custom_domain": true,
"pattern": "your-domain.com"
}
]
}``` { "$schema": "https://unpkg.com/wrangler@latest/config-schema.json", "name": "competitor-analysis", "main": "worker.ts", "compatibility_date": "2025-08-14", "assets": { "directory": "./public" }, "observability": { "logs": { "enabled": true } }, "durable_objects": { "bindings": [ { "name": "COMPETITOR_ANALYSIS", "class_name": "CompetitorAnalysisDO" } ] }, "migrations": [ { "tag": "v1", "new_sqlite_classes": ["CompetitorAnalysisDO"] } ], "routes": [ { "custom_domain": true, "pattern": "your-domain.com" } ]} ``` Or remove the `routes` section entirely to use the default `*.workers.dev` domain.
123456 # Required: Parallel API key for AI analysis
wrangler secret put PARALLEL_API_KEY
# Required: Webhook secret to receive task results
wrangler secret put PARALLEL_WEBHOOK_SECRET
# Required: Reddit MCP URL for enhanced insights
wrangler secret put MCP_URL``` # Required: Parallel API key for AI analysis wrangler secret put PARALLEL_API_KEY # Required: Webhook secret to receive task results wrangler secret put PARALLEL_WEBHOOK_SECRET # Required: Reddit MCP URL for enhanced insights wrangler secret put MCP_URL``` 1wrangler deploy```wrangler deploy```
Note: The Task API Spec is defined in `public/task.schema.json` - modify this to change what data gets analyzed based on your use case.

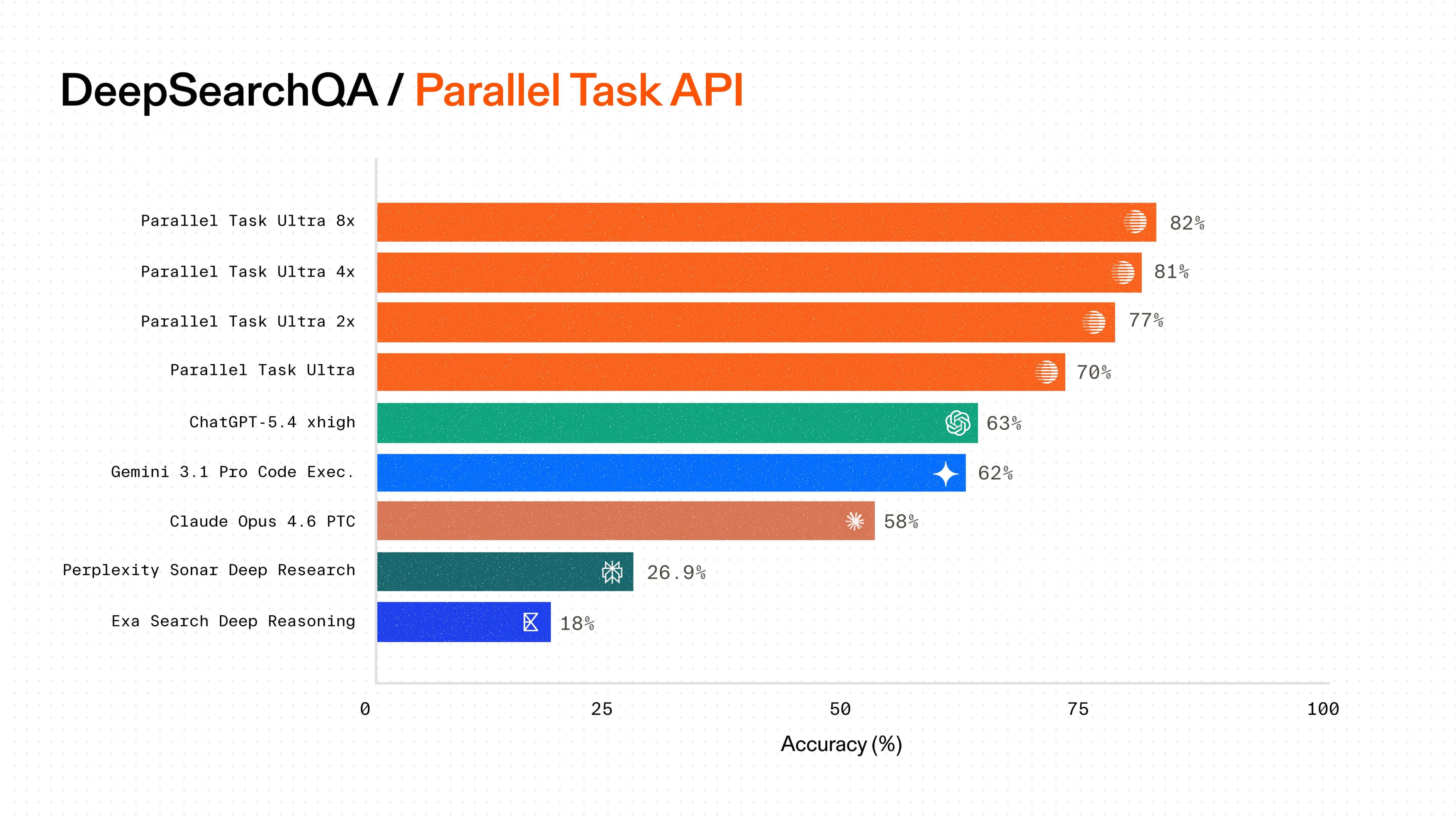
**Single Task API call vs web research pipeline**
Using the Task API provides the benefits of simplicity, quality and cost-effectiveness vs a typical web research pipeline. The Task API has been benchmarked[benchmarked](/blog/deep-research-benchmarks) against other providers to provide the best-in-class quality at each price point. It also handles the end-to-end web research pipeline, removing the need to build a pipeline that includes reasoning, search, retrieval, ranking, compression and MCP tool call configuration.
The Ultra8x processor was chosen out of each of the Task API Processor[Processor](https://docs.parallel.ai/task-api/guides/choose-a-processor) options because the user experience is designed for async research, allowing for slower-running, more in-depth research. The Ultra8x processor can also handle 25 output fields, allowing for several questions to be answered about each company – covering Reddit sentiment, investment history, feature parity, competitor mapping and more in a single API call. This removes the need for piecing together several outputs into a final format.
**Reddit MCP as a competitive research tool**
Reddit has long been considered a valuable resource for individuals to receive unfiltered reviews and advice on various products and companies. The Reddit sentiment surrounding a company is often a strong indicator of the sentiment in their broader user base. It is also an indicator of market presence and mindshare. This makes Reddit a great tool for competitive analysis. Combining comprehensive Reddit analysis with deep web research is unique and valuable for competitive insights.
**Publicly available results**
The system acts as both MCP client and server; external AI systems can consume our competitive analysis while we consume specialized analysis services. This can be very powerful as an agentic research tool; all the research done by Parallel across companies can be included as context for any further analysis.
In this application, we also implement a pipeline that combines company and competitor analyses into a single token-dense markdown context of approximately 15K tokens. This is a careful context engineering design that helps LLMs effectively interpret context from each analysis; each report is also available as a machine-friendly .md file using this approach.
**Serverless edge deployment**
Cloudflare Workers eliminate cold starts and provide global distribution. Analysis results cache at edge locations worldwide, making subsequent requests for the same company's intelligence load instantly regardless of geographic location.
**Webhooks for asynchronous processing**
Complex analysis tasks run asynchronously with webhook callbacks, preventing timeout issues while allowing users to track progress. The webhook pattern scales better than long-polling or WebSocket approaches for sporadic, compute-intensive tasks. Ultra8x Tasks are long-running, so the application prompts users to return after 30 minutes, with the webhook implementation ensuring that completion is efficiently listened for, even if the user closes the page.
**Plain HTML and JS as a frontend language**
This choice helps us reduce complexity by removing the framework to HTML+JS+CSS build-step. It incentivizes the developer to reduce the amount of complex interactions because they’re harder to make in plain HTML and JS. It also simplifies server-side rendering, resulting in highly accessible and performant dynamically generated HTML pages from our data.
This increases accessibility for both humans and machines (such as browser-agents) as complex interactions may be harder to read programmatically which could hide crucial information to AI.
Dependencies remain minimal by leveraging platform capabilities:
1234import { Queryable, QueryableHandler, studioMiddleware } from "queryable-object";
import { withMcp } from "with-mcp";
import { UserContext, withSimplerAuth } from "simplerauth-client";
import { Parallel } from "parallel-web";``` import { Queryable, QueryableHandler, studioMiddleware } from "queryable-object";import { withMcp } from "with-mcp";import { UserContext, withSimplerAuth } from "simplerauth-client";import { Parallel } from "parallel-web";``` Environment configuration focuses on service endpoints and authentication tokens rather than complex service credentials:
123456interface Env {
MCP_URL: string; // Reddit MCP server endpoint
PARALLEL_API_KEY: string; // Parallel AI service authentication
PARALLEL_WEBHOOK_SECRET: string; // Webhook signature verification
COMPETITOR_ANALYSIS_DO: DurableObjectNamespace;
}``` interface Env { MCP_URL: string; // Reddit MCP server endpoint PARALLEL_API_KEY: string; // Parallel AI service authentication PARALLEL_WEBHOOK_SECRET: string; // Webhook signature verification COMPETITOR_ANALYSIS_DO: DurableObjectNamespace;}``` The analysis data structure captures both immediate analysis results and metadata for search and discovery:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081interface AnalysisRow {
hostname: string;
company_domain: string;
company_name: string;
status: "pending" | "done";
username: string;
profile_image_url: string;
created_at: string;
updated_at: string;
visits: number;
result: string | null; // JSON string of structured analysis
error: string | null;
// Enhanced search fields extracted from analysis
category: string | null;
business_description: string | null;
industry_sector: string | null;
keywords: string | null;
}
@Queryable()
export class CompetitorAnalysisDO extends DurableObject<Env> {
sql: SqlStorage;
constructor(state: DurableObjectState, env: Env) {
super(state, env);
this.sql = state.storage.sql;
}
async createAnalysis(analysis: AnalysisRow): Promise<void> {
// Check for existing recent analysis
const results = this.sql.exec(
"SELECT * FROM analyses WHERE hostname = ? ORDER BY updated_at DESC LIMIT 1",
analysis.hostname
);
const existing = results.toArray()[0] as AnalysisRow | undefined;
if (existing?.status === "done") {
// Add your daysBetween logic here if needed
const daysDiff = daysBetween(new Date(existing.updated_at), new Date());
if (daysDiff < 14) {
throw new Error("Recent analysis exists");
}
}
this.sql.exec(
`INSERT OR REPLACE INTO analyses (hostname, company_domain, company_name, status, username, profile_image_url, created_at, updated_at, visits, result, error, category, business_description, industry_sector, keywords)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)`,
analysis.hostname,
analysis.company_domain,
analysis.company_name,
analysis.status,
analysis.username,
analysis.profile_image_url,
analysis.created_at,
analysis.updated_at,
analysis.visits || 0,
analysis.result,
analysis.error,
analysis.category,
analysis.business_description,
analysis.industry_sector,
analysis.keywords
);
}
async searchAnalyses(query: string): Promise<AnalysisRow[]> {
const lowerQuery = query.toLowerCase();
const results = this.sql.exec(
`SELECT * FROM analyses
WHERE LOWER(company_name) LIKE ?
OR LOWER(business_description) LIKE ?
OR LOWER(keywords) LIKE ?
ORDER BY visits DESC, created_at DESC
LIMIT 20`,
`%${lowerQuery}%`,
`%${lowerQuery}%`,
`%${lowerQuery}%`
);
return results.toArray() as AnalysisRow[];
}
}``` interface AnalysisRow { hostname: string; company_domain: string; company_name: string; status: "pending" | "done"; username: string; profile_image_url: string; created_at: string; updated_at: string; visits: number; result: string | null; // JSON string of structured analysis error: string | null; // Enhanced search fields extracted from analysis category: string | null; business_description: string | null; industry_sector: string | null; keywords: string | null;} @Queryable()export class CompetitorAnalysisDO extends DurableObject<Env> { sql: SqlStorage; constructor(state: DurableObjectState, env: Env) { super(state, env); this.sql = state.storage.sql; } async createAnalysis(analysis: AnalysisRow): Promise<void> { // Check for existing recent analysis const results = this.sql.exec( "SELECT * FROM analyses WHERE hostname = ? ORDER BY updated_at DESC LIMIT 1", analysis.hostname ); const existing = results.toArray()[0] as AnalysisRow | undefined; if (existing?.status === "done") { // Add your daysBetween logic here if needed const daysDiff = daysBetween(new Date(existing.updated_at), new Date()); if (daysDiff < 14) { throw new Error("Recent analysis exists"); } } this.sql.exec( `INSERT OR REPLACE INTO analyses (hostname, company_domain, company_name, status, username, profile_image_url, created_at, updated_at, visits, result, error, category, business_description, industry_sector, keywords) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)`, analysis.hostname, analysis.company_domain, analysis.company_name, analysis.status, analysis.username, analysis.profile_image_url, analysis.created_at, analysis.updated_at, analysis.visits || 0, analysis.result, analysis.error, analysis.category, analysis.business_description, analysis.industry_sector, analysis.keywords ); } async searchAnalyses(query: string): Promise<AnalysisRow[]> { const lowerQuery = query.toLowerCase(); const results = this.sql.exec( `SELECT * FROM analyses WHERE LOWER(company_name) LIKE ? OR LOWER(business_description) LIKE ? OR LOWER(keywords) LIKE ? ORDER BY visits DESC, created_at DESC LIMIT 20`, `%${lowerQuery}%`, `%${lowerQuery}%`, `%${lowerQuery}%` ); return results.toArray() as AnalysisRow[]; }}``` The 14-day refresh policy balances data freshness with processing costs. The search functionality indexes specific fields that contain the most relevant information for discovery queries.
An effective competitive analysis requires a carefully written Task Spec which aims to capture all the information required. In the Task Spec, we follow the general Task Spec guidelines:
Importantly, we also include a company_fits_criteria output field which serves as a secondary verification on the company domain, ensuring that the company is legitimate and can have a comprehensive competitive analysis done on it.
Next, the Reddit MCP server is added to the Task Spec itself as a tool, using the Tool Calling feature in the Parallel Task API:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152const performAnalysis = async (
env: Env,
do_stub: DurableObjectStub<CompetitorAnalysisDO>,
context: {
hostname: string;
isDeep: boolean;
url: URL;
username: string;
profile_image_url: string;
}
) => {
const { hostname, isDeep, url, username, profile_image_url } = context;
const parallel = new Parallel({ apiKey: env.PARALLEL_API_KEY });
const companyName = getCompanyName(hostname);
const taskRun = await parallel.beta.taskRun.create(
{
input: `Conduct comprehensive competitive intelligence analysis for company: ${hostname} including a Reddit sentiment analysis`,
processor: "ultra8x",
metadata: { hostname, isDeep, username, profile_image_url },
mcp_servers: [{ name: "Reddit", url: env.MCP_URL, type: "url" }],
webhook: {
url: `${url.protocol}//${url.host}/webhook`,
event_types: ["task_run.status"],
},
task_spec: { output_schema: { type: "json", json_schema } },
},
{
headers: {
"parallel-beta": "mcp-server-2025-07-17,webhook-2025-08-12",
},
}
);
await do_stub.createAnalysis({
hostname,
company_domain: hostname,
company_name: companyName,
status: "pending",
username: username || "",
profile_image_url: profile_image_url || "",
created_at: new Date().toISOString(),
updated_at: new Date().toISOString(),
visits: 0,
result: null,
error: null,
category: null,
business_description: null,
industry_sector: null,
keywords: null,
});
};``` const performAnalysis = async ( env: Env, do_stub: DurableObjectStub<CompetitorAnalysisDO>, context: { hostname: string; isDeep: boolean; url: URL; username: string; profile_image_url: string; }) => { const { hostname, isDeep, url, username, profile_image_url } = context; const parallel = new Parallel({ apiKey: env.PARALLEL_API_KEY }); const companyName = getCompanyName(hostname); const taskRun = await parallel.beta.taskRun.create( { input: `Conduct comprehensive competitive intelligence analysis for company: ${hostname} including a Reddit sentiment analysis`, processor: "ultra8x", metadata: { hostname, isDeep, username, profile_image_url }, mcp_servers: [{ name: "Reddit", url: env.MCP_URL, type: "url" }], webhook: { url: `${url.protocol}//${url.host}/webhook`, event_types: ["task_run.status"], }, task_spec: { output_schema: { type: "json", json_schema } }, }, { headers: { "parallel-beta": "mcp-server-2025-07-17,webhook-2025-08-12", }, } ); await do_stub.createAnalysis({ hostname, company_domain: hostname, company_name: companyName, status: "pending", username: username || "", profile_image_url: profile_image_url || "", created_at: new Date().toISOString(), updated_at: new Date().toISOString(), visits: 0, result: null, error: null, category: null, business_description: null, industry_sector: null, keywords: null, });};``` Webhook processing updates analysis results and triggers recursive competitor analysis. First, Webhook signature verification:
1234567891011const webhookId = request.headers.get("webhook-id");
const webhookTimestamp = request.headers.get("webhook-timestamp");
const webhookSignature = request.headers.get("webhook-signature");
const isSignatureValid = await verifyWebhookSignature(
env.PARALLEL_WEBHOOK_SECRET,
webhookId,
webhookTimestamp,
body,
webhookSignature
);``` const webhookId = request.headers.get("webhook-id");const webhookTimestamp = request.headers.get("webhook-timestamp");const webhookSignature = request.headers.get("webhook-signature"); const isSignatureValid = await verifyWebhookSignature( env.PARALLEL_WEBHOOK_SECRET, webhookId, webhookTimestamp, body, webhookSignature);``` Add competitor discovery logic:
1234567891011121314151617181920212223242526if (result.run.metadata?.isDeep) {
const competitors = result.output.content?.competitors as any[] | undefined;
const hostnames = competitors
?.map((comp: { hostname: string }) => comp.hostname)
.filter(Boolean);
if (hostnames?.length) {
await Promise.all(
hostnames.map(async (hostname) => {
const existingAnalysis = await do_stub.getAnalysis(hostname);
if (existingAnalysis && !existingAnalysis.error && !isAnalysisOld(existingAnalysis.updated_at)) {
return; // Skip if recent analysis exists
}
await performAnalysis(env, do_stub, {
isDeep: false, // Prevent infinite recursion
hostname,
url,
username,
profile_image_url,
});
})
);
}
}``` if (result.run.metadata?.isDeep) { const competitors = result.output.content?.competitors as any[] | undefined; const hostnames = competitors ?.map((comp: { hostname: string }) => comp.hostname) .filter(Boolean); if (hostnames?.length) { await Promise.all( hostnames.map(async (hostname) => { const existingAnalysis = await do_stub.getAnalysis(hostname); if (existingAnalysis && !existingAnalysis.error && !isAnalysisOld(existingAnalysis.updated_at)) { return; // Skip if recent analysis exists } await performAnalysis(env, do_stub, { isDeep: false, // Prevent infinite recursion hostname, url, username, profile_image_url, }); }) ); }}``` Data extraction and storage:
123456789const updateData = {
company_name: analysisData.company_name || null,
category: analysisData.category || null,
business_description: analysisData.business_description || null,
industry_sector: analysisData.industry_sector || null,
keywords: analysisData.keywords || null,
};
await do_stub.updateAnalysisResultWithData(hostname, JSON.stringify(result), null, updateData);``` const updateData = { company_name: analysisData.company_name || null, category: analysisData.category || null, business_description: analysisData.business_description || null, industry_sector: analysisData.industry_sector || null, keywords: analysisData.keywords || null,}; await do_stub.updateAnalysisResultWithData(hostname, JSON.stringify(result), null, updateData);``` The worker exposes analysis tools through MCP protocol integration:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const handler = withSimplerAuth<Env>(
async (request, env, ctx) => {
const url = new URL(request.url);
const pathname = url.pathname;
const do_id = env.COMPETITOR_ANALYSIS.idFromName("v5");
const do_stub = env.COMPETITOR_ANALYSIS.get(do_id);
// Route handling logic here...
switch (pathname) {
case "/":
return handleHome(do_stub);
case "/new":
return handleNew(request, do_stub, ctx, env);
// ... other routes
}
},
{ isLoginRequired: false }
);
return withMcp(handler, openapi, {
serverInfo: {
name: "Competitive Analysis MCP",
version: "1.0.0"
},
toolOperationIds: ["getAnalysisMarkdown"]
})(request, env, ctx);
}
};
// MCP tool implementation (for /md/ endpoint)
const getAnalysisMarkdown = async (hostname: string, env: Env): Promise<string> => {
const do_id = env.COMPETITOR_ANALYSIS.idFromName("v5");
const do_stub = env.COMPETITOR_ANALYSIS.get(do_id);
const analysis = await do_stub.getAnalysis(hostname);
if (!analysis?.result) {
throw new Error(`No analysis available for ${hostname}`);
}
const result = JSON.parse(analysis.result);
const primaryData = result.output?.content || {};
// Get competitor analyses
const competitors = primaryData.competitors || [];
const competitorHostnames = competitors
.map((comp: { hostname: string }) => comp.hostname)
.filter(Boolean);
const competitorAnalyses = await Promise.all(
competitorHostnames.map(async (compHostname: string) => {
const compAnalysis = await do_stub.getAnalysis(compHostname);
if (compAnalysis?.status === "done" && compAnalysis.result) {
const compResult = JSON.parse(compAnalysis.result);
return {
hostname: compHostname,
company_name: compAnalysis.company_name,
data: compResult.output?.content || {},
};
}
return null;
})
);
const validCompetitorAnalyses = competitorAnalyses.filter(Boolean);
return buildComprehensiveCompetitiveReport(
{ hostname, company_name: analysis.company_name, data: primaryData },
validCompetitorAnalyses
);
};``` export default { async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> { const handler = withSimplerAuth<Env>( async (request, env, ctx) => { const url = new URL(request.url); const pathname = url.pathname; const do_id = env.COMPETITOR_ANALYSIS.idFromName("v5"); const do_stub = env.COMPETITOR_ANALYSIS.get(do_id); // Route handling logic here... switch (pathname) { case "/": return handleHome(do_stub); case "/new": return handleNew(request, do_stub, ctx, env); // ... other routes } }, { isLoginRequired: false } ); return withMcp(handler, openapi, { serverInfo: { name: "Competitive Analysis MCP", version: "1.0.0" }, toolOperationIds: ["getAnalysisMarkdown"] })(request, env, ctx); }}; // MCP tool implementation (for /md/ endpoint)const getAnalysisMarkdown = async (hostname: string, env: Env): Promise<string> => { const do_id = env.COMPETITOR_ANALYSIS.idFromName("v5"); const do_stub = env.COMPETITOR_ANALYSIS.get(do_id); const analysis = await do_stub.getAnalysis(hostname); if (!analysis?.result) { throw new Error(`No analysis available for ${hostname}`); } const result = JSON.parse(analysis.result); const primaryData = result.output?.content || {}; // Get competitor analyses const competitors = primaryData.competitors || []; const competitorHostnames = competitors .map((comp: { hostname: string }) => comp.hostname) .filter(Boolean); const competitorAnalyses = await Promise.all( competitorHostnames.map(async (compHostname: string) => { const compAnalysis = await do_stub.getAnalysis(compHostname); if (compAnalysis?.status === "done" && compAnalysis.result) { const compResult = JSON.parse(compAnalysis.result); return { hostname: compHostname, company_name: compAnalysis.company_name, data: compResult.output?.content || {}, }; } return null; }) ); const validCompetitorAnalyses = competitorAnalyses.filter(Boolean); return buildComprehensiveCompetitiveReport( { hostname, company_name: analysis.company_name, data: primaryData }, validCompetitorAnalyses );};``` The MCP integration happens at the worker level, wrapping the entire application. This allows external AI systems to discover and call available tools while preserving normal HTTP functionality for web users.
Authentication applies selectively based on endpoint and functionality:
1234567891011121314151617181920// Analysis creation requires authentication
if (path === "/new") {
if (!ctx.authenticated) {
return renderLoginPage(url.searchParams.get('company'));
}
// Rate limiting for users
const do_id = env.COMPETITOR_ANALYSIS.idFromName("v5");
const do_stub = env.COMPETITOR_ANALYSIS.get(do_id);
const userAnalyses = await do_stub.getUserAnalysisCount(ctx.user?.username || "");
if (userAnalyses >= ANALYSES_LIMIT) {
return new Response(renderRateLimitPage(), {
headers: { "content-type": "text/html" }
});
}
return handleNewAnalysis(request, env, ctx);
}``` // Analysis creation requires authenticationif (path === "/new") { if (!ctx.authenticated) { return renderLoginPage(url.searchParams.get('company')); } // Rate limiting for users const do_id = env.COMPETITOR_ANALYSIS.idFromName("v5"); const do_stub = env.COMPETITOR_ANALYSIS.get(do_id); const userAnalyses = await do_stub.getUserAnalysisCount(ctx.user?.username || ""); if (userAnalyses >= ANALYSES_LIMIT) { return new Response(renderRateLimitPage(), { headers: { "content-type": "text/html" } }); } return handleNewAnalysis(request, env, ctx);}``` MCP endpoints (/md/) remain public to enable AI agent access without complex authentication flows. This design choice prioritizes AI system interoperability over access control.
Sign up for free. No credit card required.
By Parallel
September 12, 2025