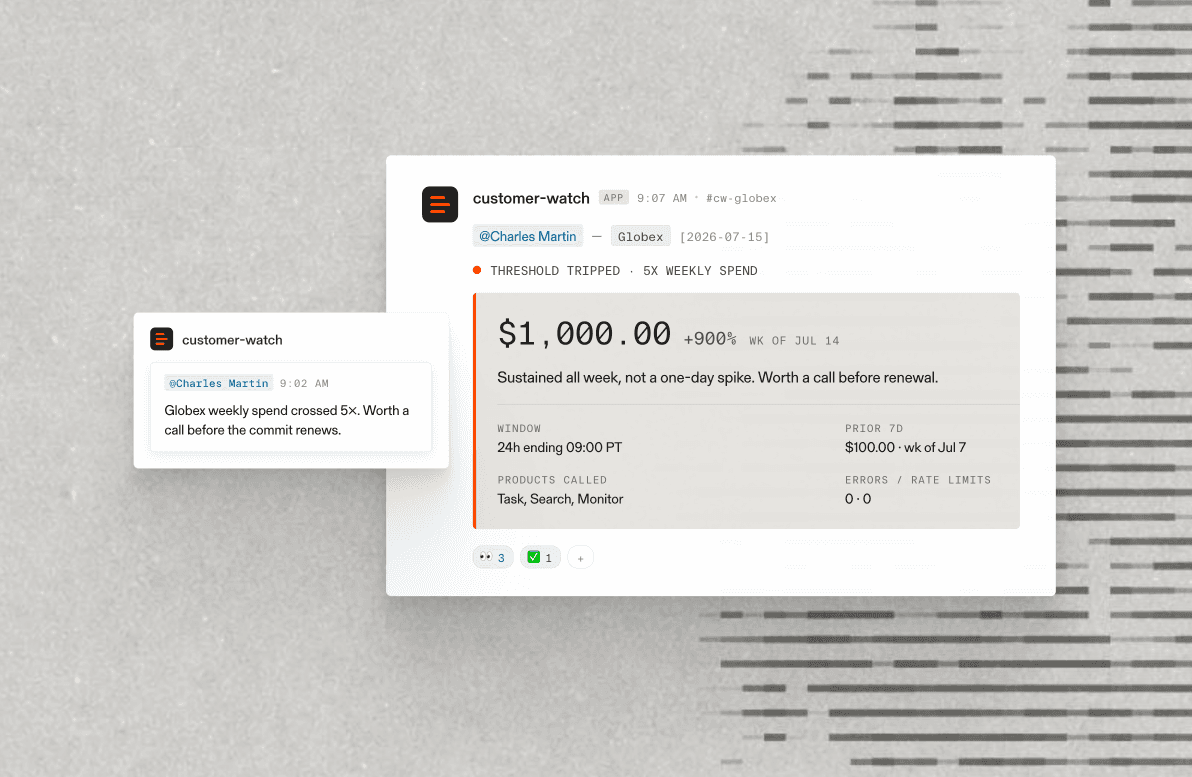
Jul 30, 2026
- [Building an always-on background agent to proactively support customers](https://parallel.ai/blog/customer-watch-background-agent)
Tags:Developers
Author: By Khushi ShelatOctober 22, 2025
This guide walks through building a comprehensive market research platform that generates detailed industry reports using Parallel's Deep Research product. The application demonstrates how to create a production-ready system that handles real-time streaming, intelligent input validation, email notifications, and robust error handling for AI-powered research tasks.

This market research platform is designed for production use with several key architectural decisions:
The platform implements two key production patterns that ensure reliability. First, **multi-layer task completion** – Tasks are monitored through background thread monitoring and each run ID is stored upon completion, allowing for state recovery if disconnected or on failure. This allows for the lower-latency ultra processors to complete gracefully and ensures reports can be tracked and kicked off concurrently.
Next, **intelligent input validation** – as a public application, it’s important to ensure the data quality to end-users is high. The Chat API is used for a low-latency verification system that checks that the inputs – market name, question, region – fit within the focus of the app, protecting against unrelated data populating the public library. This 2-step process (low-latency validation paired with high-latency deep research) is a helpful framework that can provide meaningful improvements to user experiences in other applications.
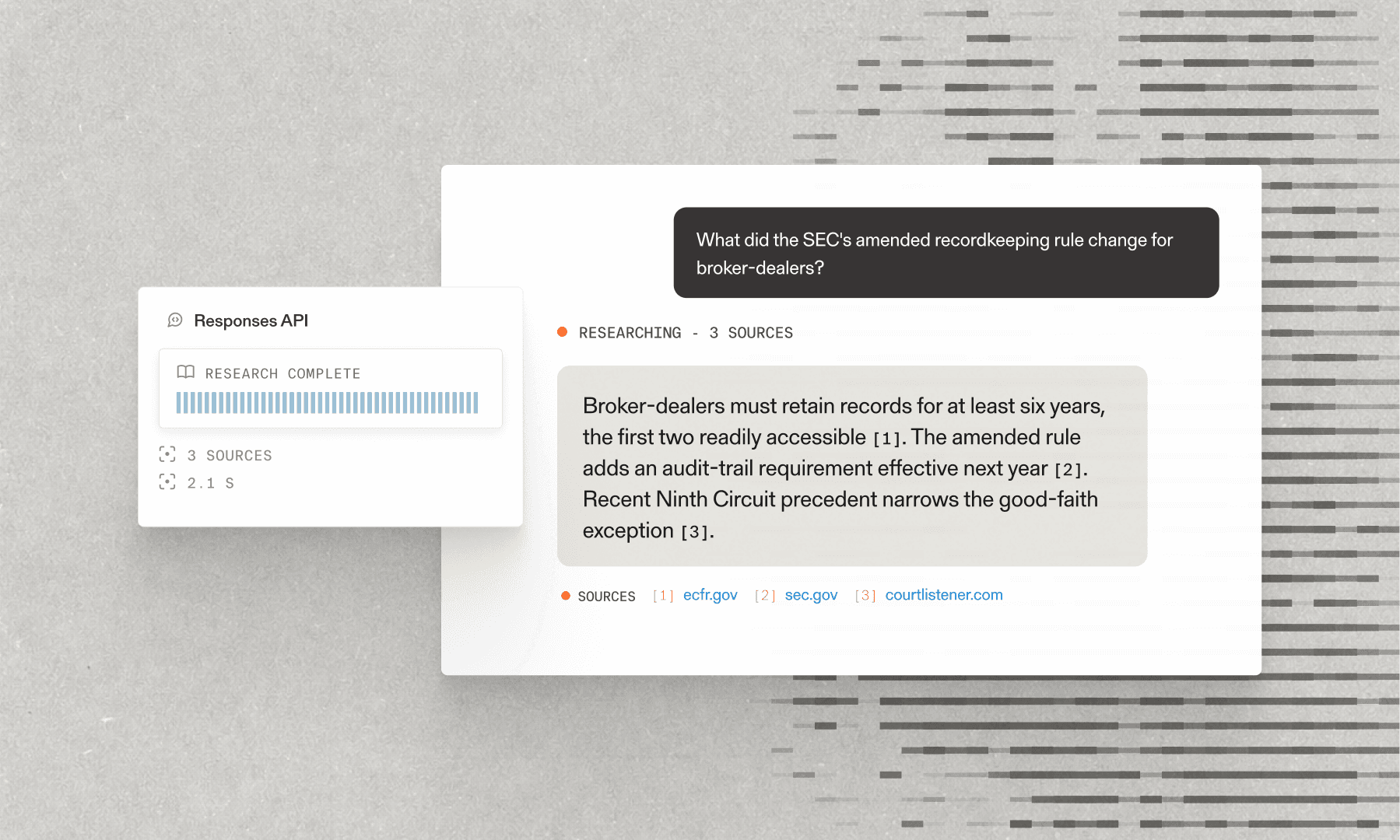
The market research platform uses Server-Sent Events (SSE) to provide live updates during report generation. This is crucial for user experience since research tasks can take 2-15 minutes to complete, and users need to understand what's happening.
The platform implements manual SSE handling rather than using the browser's built-in `EventSource` API because Parallel's API requires authentication via the `x-api-key` header, which `EventSource` doesn't support.
SSE data arrives as a continuous stream that can be split across network packets. The implementation handles this with a robust buffering system:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657def stream_task_events(task_id, api_key):
"""
Stream events from SSE endpoint with proper parsing and error handling
- Accept: text/event-stream header
- Parse 'data: {json}' format
- Yield events as generator
- Handle connection errors
"""
headers = {
'x-api-key': api_key,
'Accept': 'text/event-stream',
'Cache-Control': 'no-cache',
'parallel-beta': 'events-sse-2025-07-24'
}
stream_url = f"https://api.parallel.ai/v1beta/tasks/runs/{task_id}/events"
try:
# Use separate timeouts: (connection_timeout, read_timeout)
# Connection: 10s (should be fast), Read: 300s (allow for natural gaps in task processing)
with requests.get(stream_url, headers=headers, stream=True, timeout=(10, 300)) as response:
response.raise_for_status()
current_event_type = None
buffer = ""
for line in response.iter_lines(decode_unicode=True):
if line is None:
continue
# Handle SSE format
if line.startswith('event:'):
current_event_type = line[6:].strip()
elif line.startswith('data:'):
data_line = line[5:].strip()
if data_line:
try:
# Parse JSON data
event_data = json.loads(data_line)
# Process event based on type
processed_event = process_task_event(current_event_type, event_data)
if processed_event:
yield processed_event
except json.JSONDecodeError as e:
print(f"Failed to parse SSE event data: {data_line}, error: {e}")
continue
elif line == "":
# Empty line indicates end of event
current_event_type = None
except requests.RequestException as e:
# Let the caller handle connection errors
raise ConnectionError(f"SSE connection failed: {str(e)}")
except Exception as e:
raise RuntimeError(f"Unexpected error in SSE stream: {str(e)}")``` def stream_task_events(task_id, api_key): """ Stream events from SSE endpoint with proper parsing and error handling - Accept: text/event-stream header - Parse 'data: {json}' format - Yield events as generator - Handle connection errors """ headers = { 'x-api-key': api_key, 'Accept': 'text/event-stream', 'Cache-Control': 'no-cache', 'parallel-beta': 'events-sse-2025-07-24' } stream_url = f"https://api.parallel.ai/v1beta/tasks/runs/{task_id}/events" try: # Use separate timeouts: (connection_timeout, read_timeout) # Connection: 10s (should be fast), Read: 300s (allow for natural gaps in task processing) with requests.get(stream_url, headers=headers, stream=True, timeout=(10, 300)) as response: response.raise_for_status() current_event_type = None buffer = "" for line in response.iter_lines(decode_unicode=True): if line is None: continue # Handle SSE format if line.startswith('event:'): current_event_type = line[6:].strip() elif line.startswith('data:'): data_line = line[5:].strip() if data_line: try: # Parse JSON data event_data = json.loads(data_line) # Process event based on type processed_event = process_task_event(current_event_type, event_data) if processed_event: yield processed_event except json.JSONDecodeError as e: print(f"Failed to parse SSE event data: {data_line}, error: {e}") continue elif line == "": # Empty line indicates end of event current_event_type = None except requests.RequestException as e: # Let the caller handle connection errors raise ConnectionError(f"SSE connection failed: {str(e)}") except Exception as e: raise RuntimeError(f"Unexpected error in SSE stream: {str(e)}")``` This approach ensures reliable parsing of SSE events even when network packets split messages unpredictably.
Since market research tasks can take 2-15 minutes, the platform implements robust reconnection logic to handle network interruptions:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556def monitor_task_completion_robust(task_id, api_key, max_reconnects=10):
"""
Monitor task with robust reconnection using exponential backoff
Returns: (task_completed: bool, final_status: str, error_msg: str)
"""
task_completed = False
final_status = None
error_msg = None
reconnect_count = 0
print(f"Starting robust monitoring for task {task_id}")
while not task_completed and reconnect_count < max_reconnects:
try:
print(f"Monitoring attempt {reconnect_count + 1}/{max_reconnects}")
# Stream events with timeout
for event in stream_task_events(task_id, api_key):
if event.get('type') == 'task.status':
final_status = event.get('status')
task_completed = event.get('is_complete', False)
if task_completed:
print(f"Task {task_id} completed with status: {final_status}")
return task_completed, final_status, None
elif event.get('type') == 'error':
error_msg = event.get('message', 'Unknown error')
print(f"Task {task_id} error: {error_msg}")
# Check if this is a recoverable error
if is_recoverable_error(error_msg):
break # Break to retry
else:
return False, 'failed', error_msg
except (ConnectionError, requests.RequestException) as e:
# Network errors are recoverable
print(f"Connection error for task {task_id}: {e}")
reconnect_count += 1
if reconnect_count < max_reconnects:
# Exponential backoff: wait_time = min(2 ** retry_count, 30)
wait_time = min(2 ** reconnect_count, 30)
print(f"Waiting {wait_time}s before reconnection attempt {reconnect_count + 1}")
time.sleep(wait_time)
else:
error_msg = f"Max reconnection attempts reached after {max_reconnects} tries"
except Exception as e:
# Unexpected errors
error_msg = f"Unexpected monitoring error: {str(e)}"
print(f"Unexpected error for task {task_id}: {e}")
break
return task_completed, final_status, error_msg``` def monitor_task_completion_robust(task_id, api_key, max_reconnects=10): """ Monitor task with robust reconnection using exponential backoff Returns: (task_completed: bool, final_status: str, error_msg: str) """ task_completed = False final_status = None error_msg = None reconnect_count = 0 print(f"Starting robust monitoring for task {task_id}") while not task_completed and reconnect_count < max_reconnects: try: print(f"Monitoring attempt {reconnect_count + 1}/{max_reconnects}") # Stream events with timeout for event in stream_task_events(task_id, api_key): if event.get('type') == 'task.status': final_status = event.get('status') task_completed = event.get('is_complete', False) if task_completed: print(f"Task {task_id} completed with status: {final_status}") return task_completed, final_status, None elif event.get('type') == 'error': error_msg = event.get('message', 'Unknown error') print(f"Task {task_id} error: {error_msg}") # Check if this is a recoverable error if is_recoverable_error(error_msg): break # Break to retry else: return False, 'failed', error_msg except (ConnectionError, requests.RequestException) as e: # Network errors are recoverable print(f"Connection error for task {task_id}: {e}") reconnect_count += 1 if reconnect_count < max_reconnects: # Exponential backoff: wait_time = min(2 ** retry_count, 30) wait_time = min(2 ** reconnect_count, 30) print(f"Waiting {wait_time}s before reconnection attempt {reconnect_count + 1}") time.sleep(wait_time) else: error_msg = f"Max reconnection attempts reached after {max_reconnects} tries" except Exception as e: # Unexpected errors error_msg = f"Unexpected monitoring error: {str(e)}" print(f"Unexpected error for task {task_id}: {e}") break return task_completed, final_status, error_msg``` The reconnection system includes exponential backoff, attempt limiting, and status-based retry logic to ensure reliable task completion.
The platform processes different types of events from Parallel's SSE stream, each serving specific purposes in the user interface. In the below code snippet, we demonstrated how each type of event was handled for display:
123456789101112131415161718192021222324252627def process_task_event(event_type, event_data):
"""
Process different event types from Parallel API
Returns standardized event format for frontend
"""
processed = {
'timestamp': event_data.get('timestamp'),
'raw_type': event_data.get('type', event_type)
}
# Handle different event types
if event_data.get('type') == 'task_run.state':
run_info = event_data.get('run', {})
status = run_info.get('status', 'unknown')
processed.update({
'type': 'task.status',
'status': status,
'is_complete': status in ['completed', 'failed', 'cancelled'],
'message': f"Task status: {status}",
'category': 'status'
})
elif event_data.get('type') == 'task_run.progress_stats':
# continue through each event type
return processed``` def process_task_event(event_type, event_data): """ Process different event types from Parallel API Returns standardized event format for frontend """ processed = { 'timestamp': event_data.get('timestamp'), 'raw_type': event_data.get('type', event_type) } # Handle different event types if event_data.get('type') == 'task_run.state': run_info = event_data.get('run', {}) status = run_info.get('status', 'unknown') processed.update({ 'type': 'task.status', 'status': status, 'is_complete': status in ['completed', 'failed', 'cancelled'], 'message': f"Task status: {status}", 'category': 'status' }) elif event_data.get('type') == 'task_run.progress_stats': # continue through each event type return processed ``` The system handles multiple event types:
This event diversity enables rich UI updates including progress bars, reasoning displays, and comprehensive error handling.
When reports complete, the platform automatically notifies users via email using the Resend API:
123456789101112131415161718192021222324252627282930313233def send_report_ready_email(email, report_title, report_slug, task_id):
"""Send email notification when report is ready using Resend API"""
if not RESEND_API_KEY or not email:
print(f"Skipping email: RESEND_API_KEY={'present' if RESEND_API_KEY else 'missing'}, email={'present' if email else 'missing'}")
return False
try:
# Build the report URL
report_url = f"{BASE_URL}/report/{report_slug}"
# Render the email HTML template
html_content = render_template(
'email_report_ready.html',
report_title=report_title,
report_url=report_url,
task_id=task_id
)
# Prepare email data
email_data = {
"from": "Market Research <updates@aimarketresearch.app>",
"to": [email],
"subject": "Market Research report is now available",
"html": html_content,
"reply_to": "updates@aimarketresearch.app"
}
# Send email via Resend API
headers = {
'Authorization': f'Bearer {RESEND_API_KEY}',
'Content-Type': 'application/json'
}``` def send_report_ready_email(email, report_title, report_slug, task_id): """Send email notification when report is ready using Resend API""" if not RESEND_API_KEY or not email: print(f"Skipping email: RESEND_API_KEY={'present' if RESEND_API_KEY else 'missing'}, email={'present' if email else 'missing'}") return False try: # Build the report URL report_url = f"{BASE_URL}/report/{report_slug}" # Render the email HTML template html_content = render_template( 'email_report_ready.html', report_title=report_title, report_url=report_url, task_id=task_id ) # Prepare email data email_data = { "from": "Market Research <updates@aimarketresearch.app>", "to": [email], "subject": "Market Research report is now available", "html": html_content, "reply_to": "updates@aimarketresearch.app" } # Send email via Resend API headers = { 'Authorization': f'Bearer {RESEND_API_KEY}', 'Content-Type': 'application/json' } ``` The platform uses a unified PostgreSQL schema that efficiently stores both running tasks and completed reports in a single table:
12345678910111213141516171819-- Unified reports table handling both running tasks and completed reports CREATE TABLE reports ( id VARCHAR PRIMARY KEY, task_run_id VARCHAR UNIQUE NOT NULL, title VARCHAR, slug VARCHAR UNIQUE, industry VARCHAR NOT NULL, geography VARCHAR, details TEXT, content TEXT, basis JSONB, status VARCHAR DEFAULT 'running', session_id VARCHAR, email VARCHAR, is_public BOOLEAN DEFAULT TRUE, error_message TEXT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, completed_at TIMESTAMP );```-- Unified reports table handling both running tasks and completed reportsCREATE TABLE reports (id VARCHAR PRIMARY KEY,task_run_id VARCHAR UNIQUE NOT NULL,title VARCHAR,slug VARCHAR UNIQUE,industry VARCHAR NOT NULL,geography VARCHAR,details TEXT,content TEXT,basis JSONB,status VARCHAR DEFAULT 'running',session_id VARCHAR,email VARCHAR,is_public BOOLEAN DEFAULT TRUE,error_message TEXT,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,completed_at TIMESTAMP);```
This design enables efficient querying of both active tasks and completed reports while supporting the public report library feature.
Sign up for free. No credit card required.
By Parallel
October 22, 2025