Jul 21, 2026
- [Introducing the Parallel Responses API](https://parallel.ai/blog/responses-api)
Tags:Product
Author: By ParallelApril 24, 2025
The state-of-the-art system for automated web research

At Parallel Web Systems[Parallel Web Systems], we’ve been busy building infrastructure for a web built for AIs[building infrastructure for a web built for AIs]. Today, we’re excited to announce our first product: the Parallel Task API.
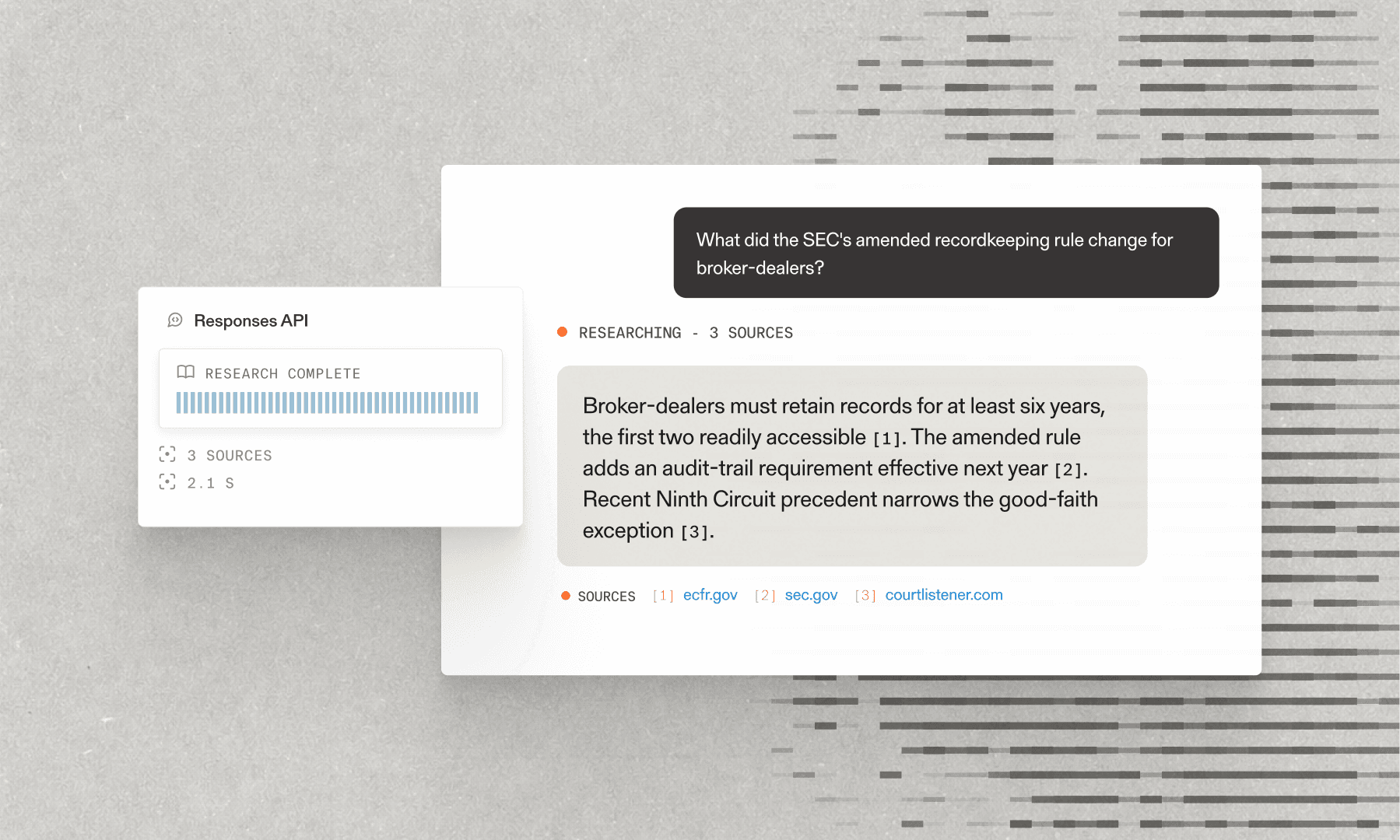
The Parallel Task API[Parallel Task API] offers developers and enterprises a robust, reliable, and highly scalable solution for obtaining data, research findings, and insights from the internet. It has been built and optimized for repeated workflows over information on the open web that demand scalability and quality. Instead of engineering bespoke and complex AI+human workflows, users simply declare what information and insights they need. Our API seamlessly orchestrates the querying, ranking, retrieval, reasoning, validation, and synthesis to deliver this information as structured outputs.
Beyond simplifying the interface for our customers, our declarative approach enables optimization across a wide range of query plans, resulting in unprecedented accuracy. We provide customers with a choice of processors, each with a budget across compute and retrieval, and automatically optimized to achieve peak performance. This allows us to offer simple, transparent, and predictable pricing while delivering the highest quality results across a wide range of use cases across a wide range of price points.
1234567891011121314151617181920212223from parallel import Parallel
from pydantic import BaseModel, Field
class ProductInfo(BaseModel):
use_cases: str = Field(
description="A few use cases for the product."
)
differentiators: str = Field(
description="3 unique differentiators for the product as a bullet list."
)
benchmarks: str = Field(
description="Detailed benchmarks of the product reported by the company."
)
client = Parallel()
result = client.task_run.execute(
input="Parallel Web Systems Task API",
output=ProductInfo,
processor="core"
)
print(f"Product info: {result.output.parsed.model_dump_json(indent=2)}\n")
print(f"Basis: {'\n'.join([b.model_dump_json(indent=2) for b in result.output.basis])}")``` from parallel import Parallelfrom pydantic import BaseModel, Field class ProductInfo(BaseModel): use_cases: str = Field( description="A few use cases for the product." ) differentiators: str = Field( description="3 unique differentiators for the product as a bullet list." ) benchmarks: str = Field( description="Detailed benchmarks of the product reported by the company." ) client = Parallel()result = client.task_run.execute( input="Parallel Web Systems Task API", output=ProductInfo, processor="core") print(f"Product info: {result.output.parsed.model_dump_json(indent=2)}\n")print(f"Basis: {'\n'.join([b.model_dump_json(indent=2) for b in result.output.basis])}")``` Every response includes comprehensive citations linking to source materials and detailed reasoning for every output field. For most processors, we also provide confidence scores that are calibrated to reflect the uncertainty for each output field. These features make the Parallel Task API an ideal choice for production systems and workflows with the most exacting requirements for accuracy, scale, and auditability.
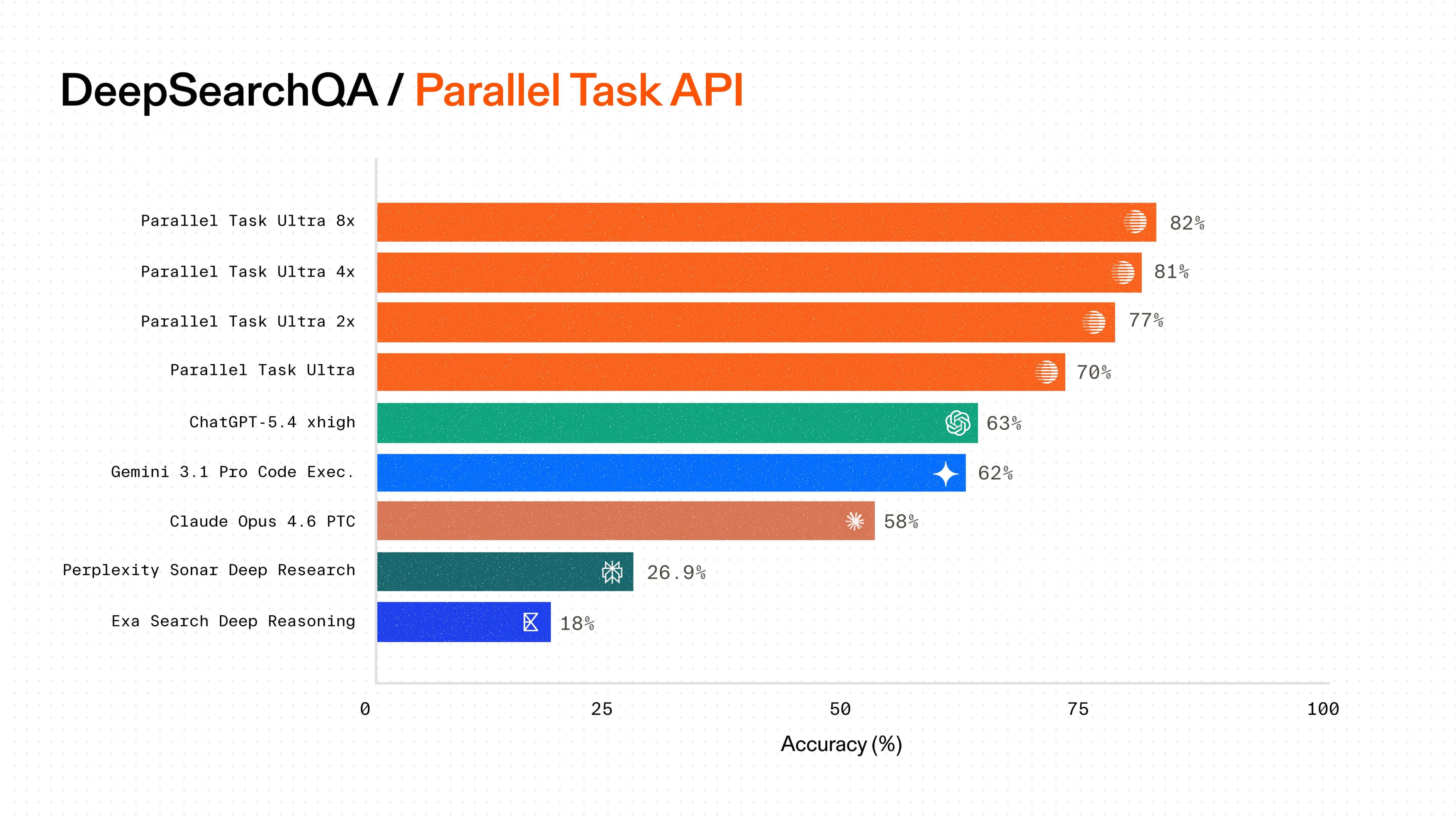
The Parallel Task API sets a new standard on web research benchmarks, both academic and ones we’ve built inspired by actual customer use cases spanning several domains.
Accuracy (%)
COST (CPM )
ACCURACY (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark, created by Parallel, contains 121 questions intended to reflect real-world web research queries across a variety of domains.
50% Multi-Hop questions
50% Single-Hop questions
40% Financial Research
20% Sales Research
20% Recruitment
20% Miscellaneous
This benchmark, created by Parallel, contains 121 questions intended to reflect real-world web research queries across a variety of domains.
50% Multi-Hop questions
50% Single-Hop questions
40% Financial Research
20% Sales Research
20% Recruitment
20% Miscellaneous
| Series | Model | Cost (CPM ) | Accuracy (%) | | -------- | ---------------- | ----------- | ------------ | | Parallel | Lite | 5 | 64 | | Parallel | Base | 10 | 75 | | Parallel | Core | 25 | 77 | | Others | o3 | 45 | 69 | | Others | o4 mini low | 31 | 68 | | Others | 4.1 mini low | 25 | 63 | | Others | gemini 2.5 flash | 35 | 53 | | Others | gemini 2.5 pro | 36 | 56 | | Others | sonar pro high | 16 | 64 | | Others | sonar pro low | 7 | 59 | | Others | sonar low | 5 | 48 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark, created by Parallel, contains 121 questions intended to reflect real-world web research queries across a variety of domains.
50% Multi-Hop questions
50% Single-Hop questions
40% Financial Research
20% Sales Research
20% Recruitment
20% Miscellaneous
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ---------------- | ---------- | ------------ | | Parallel | Core | 25 | 94 | | Parallel | Base | 10 | 94 | | Parallel | Lite | 5 | 92 | | Others | o3 high | 56 | 92 | | Others | gemini 2.5 flash | 35 | 91 | | Others | 4.1 mini high | 30 | 88 | | Others | sonar pro | 13 | 84 | | Others | sonar | 8 | 81 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark contains 4,326 questions focused on short, fact-seeking queries across a variety of domains.
100% Single-Hop questions
36% Culture
20% Science and Technology
16% Politics
28% Miscellaneous
While SimpleQA[SimpleQA] measures factual accuracy on straightforward questions, we developed a proprietary benchmark suite called WISER that tests real-world, customer-inspired use cases across financial research, sales intelligence, recruitment, and other domains. Beyond just achieving the highest accuracy score, we outperform leading alternatives at every price point establishing a new pareto-frontier for both SimpleQA and WISER-Atomic.
Today, Parallel powers production-grade workflows across a range of domains. As a SOC-II Type 2 certified platform, we're trusted by startups and enterprises alike to get structured insights from the web reliably and at scale. Our API serves diverse use cases across domains: insurance underwriters evaluating business risks, sales teams enriching CRM data with company intelligence, financial analysts conducting due diligence or sourcing, and professional service firms streamlining manual research workflows. The Task API is available today - we are excited to discover and serve use cases beyond our imagination.
To start building on our developer platform, request access[request access].
**Standalone LLMs:** While some might be tempted to compare Parallel to plain LLMs (e.g., GPT-4.5), we consider this a different category because standalone LLMs lack real-time web access. That said, the best standalone model we tested—GPT-4.5—achieved around 62.5% SimpleQA accuracy, which is impressive in its own right. However, it cannot update from current data or retrieve verified web sources in real time.
**Models and competitors used: **For providers with publicly comparable AI-based web search APIs, we used all available configurations. However, given some providers have a large number of configurations, we show and report only the configurations on the provider’s own price-performance frontier on the WISER-Atomic benchmark. For SimpleQA, we chose 2-3 diverse configurations per provider to measure and report.** **Perplexity reports an accuracy score of 93.9% for their Deep Research implementation on SimpleQA. On WISER-Atomic, Perplexity Deep Research scores 64% with an average cost of 290 CPM over the benchmark.
**LLM Evaluator:** Each system's responses were scored by the same standard with the same evaluator and evaluation criteria. For SimpleQA, we used the standard evaluator. For our internal benchmark, we used our proprietary evaluator.
**Benchmark Dates:** Testing was conducted between April 21 and April 24, 2025.
**Benchmark Details: **For all models, we ran the full SimpleQA benchmark (~4,300 questions in total). While our internal benchmark is large and contains more complex tasks, we report on a test set of 121 questions that we refer to as the WISER-Atomic (Web Intelligence Search Evaluation Research) dataset. Three example questions are below.
**Limitations: **There are differences in the latency of each model, which we do not report in this post. Most notably, the Parallel processors tested are slower than the competitors.
**Cost Standardization:** Pricing models vary across all providers benchmarked. Parallel has a standardized and transparent per-query pricing model. For APIs with token-based billing (OpenAI, Perplexity, etc.), we used publicly listed prices and normalized them to a consistent cost per thousand queries (CPM) as measured on the benchmark. As a result, the prices for the same model may vary across benchmarks.
**Example questions from WISER-Atomic**
1234567891011Sample queries from WISER-ATOMIC (April 2025)
## Financial Research
query: In fiscal year 2024, what percentage of Salesforce's subscription and support revenue came from the segment that includes its Tableau acquisition, and how does this compare to the company's overall CRM market share in 2023? Please share all of your factual findings that helped you answer the question, in your final answer.
## Economics
query: According to the International Debt Statistics 2023 by the World Bank, calculate the average Foreign Direct Investment amount (in millions of USD) for Sri Lanka,Turkmenistan, and Niger in 2019. Round your answer to two decimal places.
## Sales Research
query: Navigate to the website in http://www.flightaware.com. This is the main domain for the target company.
Once you are on their website, locate their careers or jobs page. Print the careers page URL.``` Sample queries from WISER-ATOMIC (April 2025) ## Financial Researchquery: In fiscal year 2024, what percentage of Salesforce's subscription and support revenue came from the segment that includes its Tableau acquisition, and how does this compare to the company's overall CRM market share in 2023? Please share all of your factual findings that helped you answer the question, in your final answer. ## Economicsquery: According to the International Debt Statistics 2023 by the World Bank, calculate the average Foreign Direct Investment amount (in millions of USD) for Sri Lanka,Turkmenistan, and Niger in 2019. Round your answer to two decimal places. ## Sales Researchquery: Navigate to the website in http://www.flightaware.com. This is the main domain for the target company. Once you are on their website, locate their careers or jobs page. Print the careers page URL.``` Sign up for free. No credit card required.
By Parallel
April 24, 2025