Jul 21, 2026
- [Introducing the Parallel Responses API](https://parallel.ai/blog/responses-api)
Tags:Product
Author: By ParallelMay 16, 2025
A new standard for verifiable AI web research

A month ago, we launched the Parallel Task API, powered by a series of processors that offer state of the art accuracy on web research tasks at every single price point.
We recognize, however, that production use case don't just require pareto-optimal performance — they also require verifiability and calibrated confidence scoring and so today, we're excited to announce Basis — an essential suite of verification tools for the Parallel Task API.
Basis is an automatically included add-on to our Core, Pro, and Ultra processors that provide additional context and evidence around how we came to our conclusion, as well as how confident we are in our findings.
They allow you to identify instances where AI web research may yield unreliable results, enabling targeted human-in-the-loop workflows that efficiently focus human attention only where it's most needed. This strategic approach drastically reduces manual review hours while achieving significantly higher accuracy in hybrid human/AI workflows compared to either AI-only or human-only alternatives.
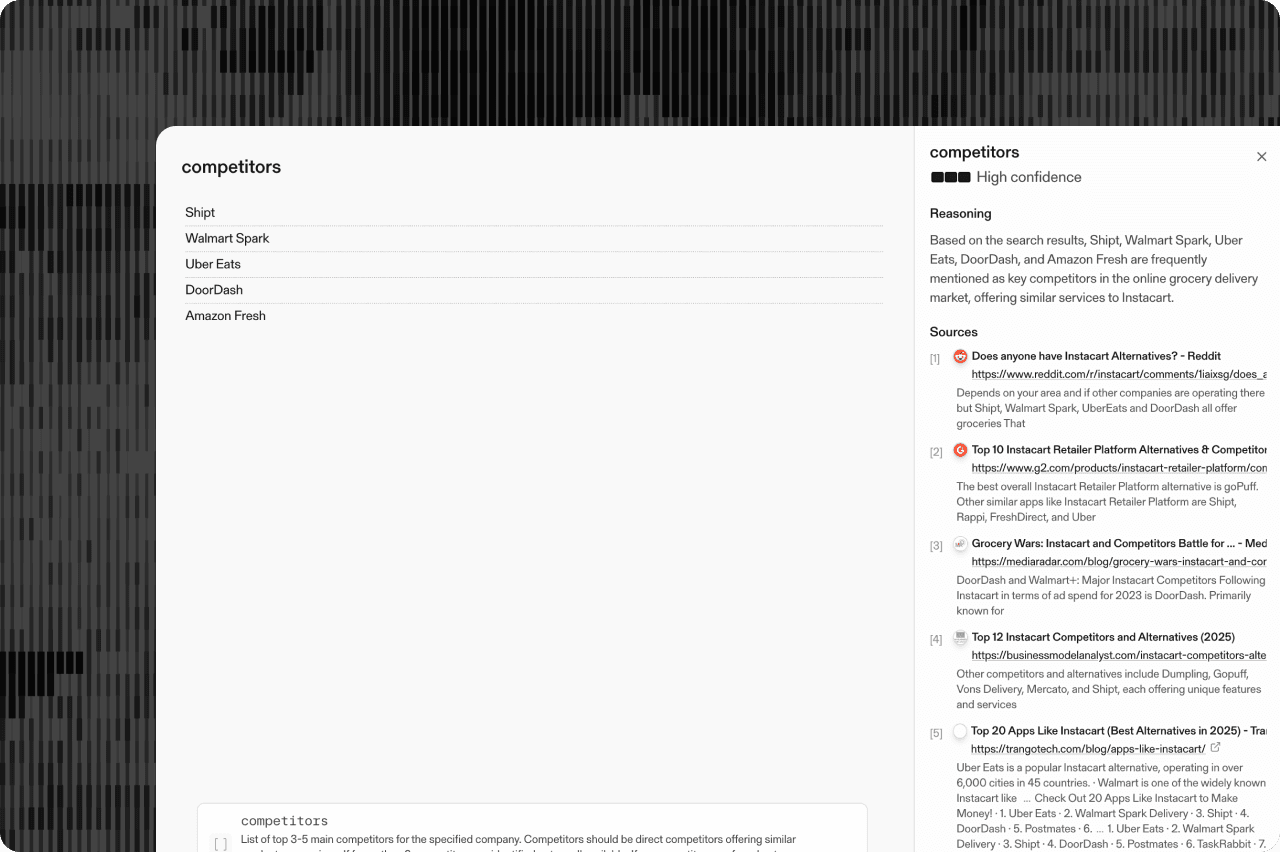
Basis provides a complete framework for understanding and validating Task API outputs through four core components:
These elements work together to create a robust framework for output verification that sets a new industry standard for transparency and reliability. For more information on Basis outputs in our Task API, go to docs[docs].
1234567891011{
"field": "crm_system",
"citations": [
{
"url": "https://www.linkedin.com/jobs/view/sales-representative-microsoft-dynamics-365-at-contoso-inc-3584271",
"excerpts": ["Looking for sales professionals with experience in Microsoft Dynamics 365 CRM to join our growing team."]
}
],
"reasoning": "There is limited direct evidence about which CRM system the company uses internally. The job posting suggests they work with Microsoft Dynamics 365, but it's not explicitly stated whether this is their primary internal CRM or simply a product they sell/support. No official company documentation confirming their internal CRM system was found.",
"confidence": "low"
}``` { "field": "crm_system", "citations": [ { "url": "https://www.linkedin.com/jobs/view/sales-representative-microsoft-dynamics-365-at-contoso-inc-3584271", "excerpts": ["Looking for sales professionals with experience in Microsoft Dynamics 365 CRM to join our growing team."] } ], "reasoning": "There is limited direct evidence about which CRM system the company uses internally. The job posting suggests they work with Microsoft Dynamics 365, but it's not explicitly stated whether this is their primary internal CRM or simply a product they sell/support. No official company documentation confirming their internal CRM system was found.", "confidence": "low"}``` Confidence ratings aren't particularly useful without calibration — you need to know that high, medium, and low labels provide useful and differentiable insight into task performance.
To calibrate confidence ratings, we’ve tested confidence patterns on composite datasets that reflect a wide array of real world use cases. Each composite dataset has varying levels of difficulty to demonstrate confidence performance and distribution across any web research task.
Why is this important?
When Parallel returns a higher percentage of Basis outputs as "High" Confidence, you can reliably interpret this as Parallel's Task API performing well on the Task.
You can use confidences as a proxy for a full evaluation, and understand how well your Tasks perform relative to each other.
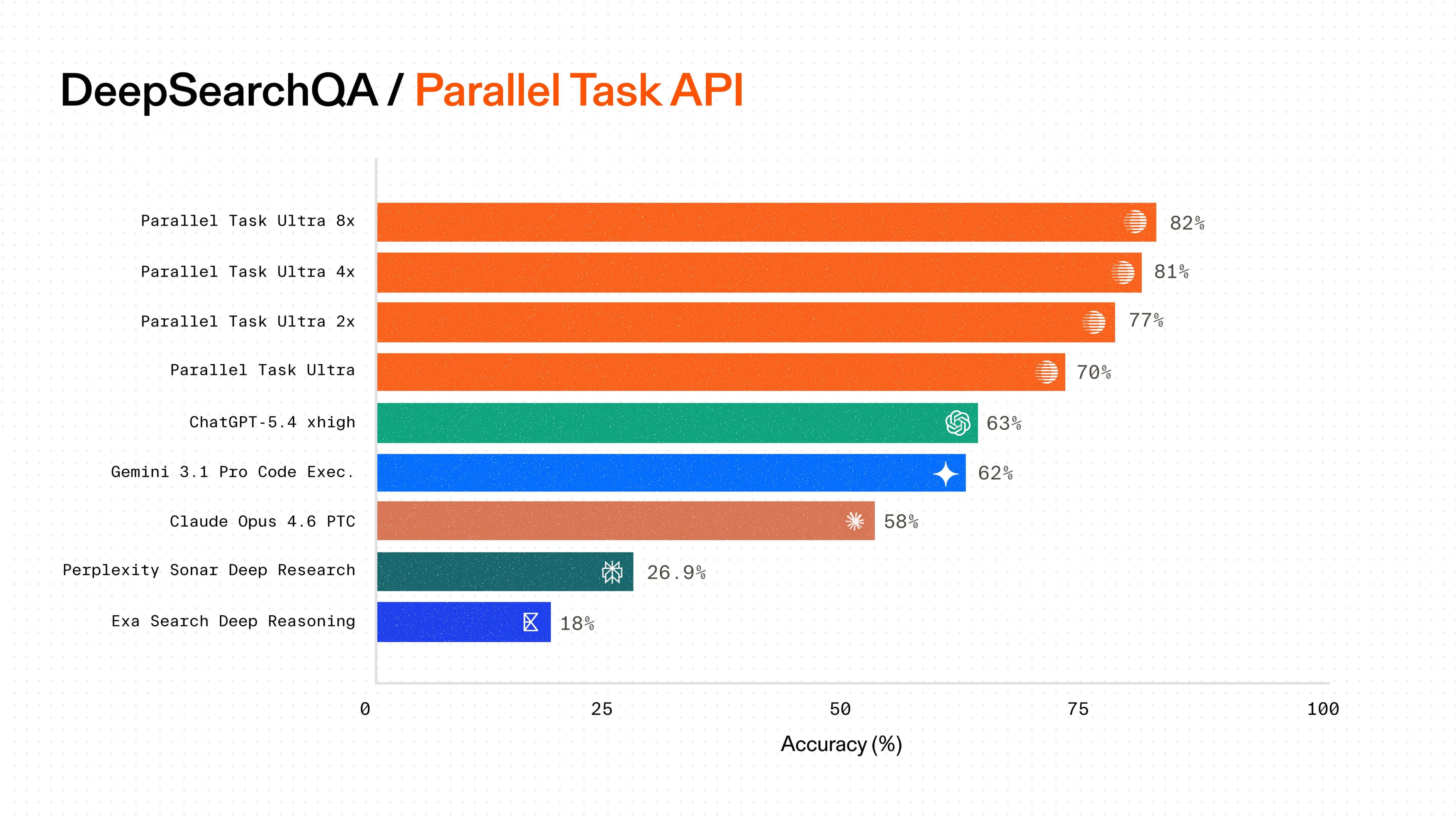
Overall Dataset Accuracy (%)
HIGH CONFIDENCE RESPONSES (%)
OVERALL DATASET ACCURACY (%)
For each dataset (Easy, Medium, Hard) - the % of answers that are High Confidence compared to the overall accuracy % of the dataset.
As dataset queries get easier (ie higher overall accuracy %), the % of High Confidence responses increases.
This demonstrates confidences can reliably be used as a proxy for evaluating Parallel Processor performance on a dataset.
For each dataset (Easy, Medium, Hard) - the % of answers that are High Confidence compared to the overall accuracy % of the dataset.
As dataset queries get easier (ie higher overall accuracy %), the % of High Confidence responses increases.
This demonstrates confidences can reliably be used as a proxy for evaluating Parallel Processor performance on a dataset.
| Series | Model | High Confidence Responses (%) | Overall Dataset Accuracy (%) | | ------- | ------ | ----------------------------- | ---------------------------- | | Easy | Easy | 78 | 91 | | Medium | Medium | 72 | 80 | | Hard | Hard | 53 | 70 |
For each dataset (Easy, Medium, Hard) - the % of answers that are High Confidence compared to the overall accuracy % of the dataset.
As dataset queries get easier (ie higher overall accuracy %), the % of High Confidence responses increases.
This demonstrates confidences can reliably be used as a proxy for evaluating Parallel Processor performance on a dataset.
By reviewing just the outputs rated as "Low" Confidence—a small portion of your total dataset—you can typically achieve an ~2x reduction in error rate, giving you significantly more leverage over human time compared to reviewing all outputs.
Outputs marked as "High" Confidence have 2-3X lower error rates than that of the overall dataset.
Basis is particularly valuable for hybrid AI-human workflows where the addition of AI significantly increases leverage, accuracy, and time efficiency. By focusing human review on outputs with low confidence, teams can dramatically reduce verification time while maintaining quality standards. This approach allows enterprises to scale their web research operations without sacrificing accuracy or transparency.
Today, Basis powers human-in-the-loop production workflows across numerous domains. Insurance underwriters leverage low-confidence indicators and citation trails to streamline KYB verification processes that were previously manual. AI automation platforms use Basis to validate data enrichment capabilities before pushing to production, providing traceability from enriched fields back to source materials.
The Basis framework with calibrated confidences is available today with the Parallel Task API. To start building with verifiable web research, go to the Parallel Developer Platform[Parallel Developer Platform].
**Testing Dates**: Testing was conducted between May 12 and May 15, 2025
**Benchmark Details**: The Parallel Confidence datasets cover easy, medium, and hard web research questions that all reflect a wide range of representative real world use cases. Three example questions are below.
**Example Questions**:
**Additional Data: **
| Category | Correct (%) | Incorrect (%) | | -------- | ----------- | ------------- | | High | 97.2 | 2.8 | | Medium | 71.9 | 28.1 | | Low | 64.5 | 35.5 | | | 0 | 0 | | High | 97.5 | 2.5 | | Medium | 82.6 | 17.4 | | Low | 37.5 | 62.5 | | | 0 | 0 | | High | 85.9 | 14.1 | | Medium | 80 | 20 | | Low | 36.1 | 63.9 |
| Category | Incorrect ( ) | Correct ( ) | | -------- | ------------- | ----------- | | High | 6 | 211 | | Medium | 9 | 23 | | Low | 11 | 20 | | | 0 | 0 | | High | 3 | 116 | | Medium | 4 | 19 | | Low | 10 | 6 | | | 0 | 0 | | High | 9 | 55 | | Medium | 4 | 16 | | Low | 23 | 13 |
Sign up for free. No credit card required.
By Parallel
May 16, 2025