Jul 30, 2026
- [Building an always-on background agent to proactively support customers](https://parallel.ai/blog/customer-watch-background-agent)
Tags:Developers
Author: By Khushi ShelatApril 7, 2026
The Parallel Task API is the most powerful deep research agent on the market. It’s used in production agents by teams at Opendoor, Attio, Modal, Starbridge, Profound, and more.
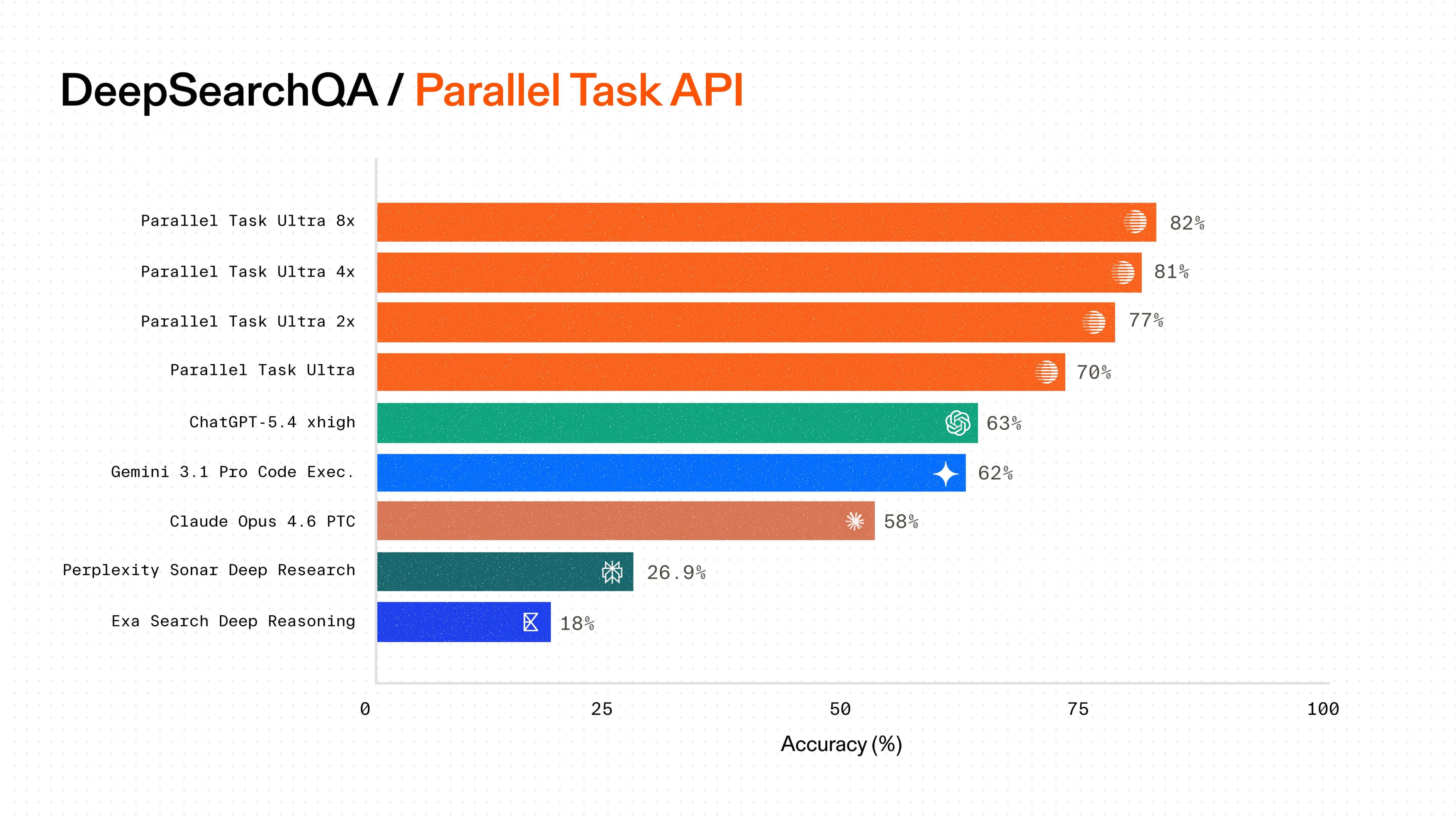
Parallel’s Processor[Processor] architecture allows for flexibility and fine-tuned application of different compute budgets depending on the complexity of a research task. The “Ultra” range of Task API Processors is state-of-the-art on DeepSearchQA:
This blog details some of the techniques we’ve employed to achieve this state of the art research quality.
We evaluated Parallel's Task API Processors against GPT 5.4, Opus 4-6, Gemini 3.1 Pro, Exa Search Deep Reasoning, and Perplexity Sonar Pro.
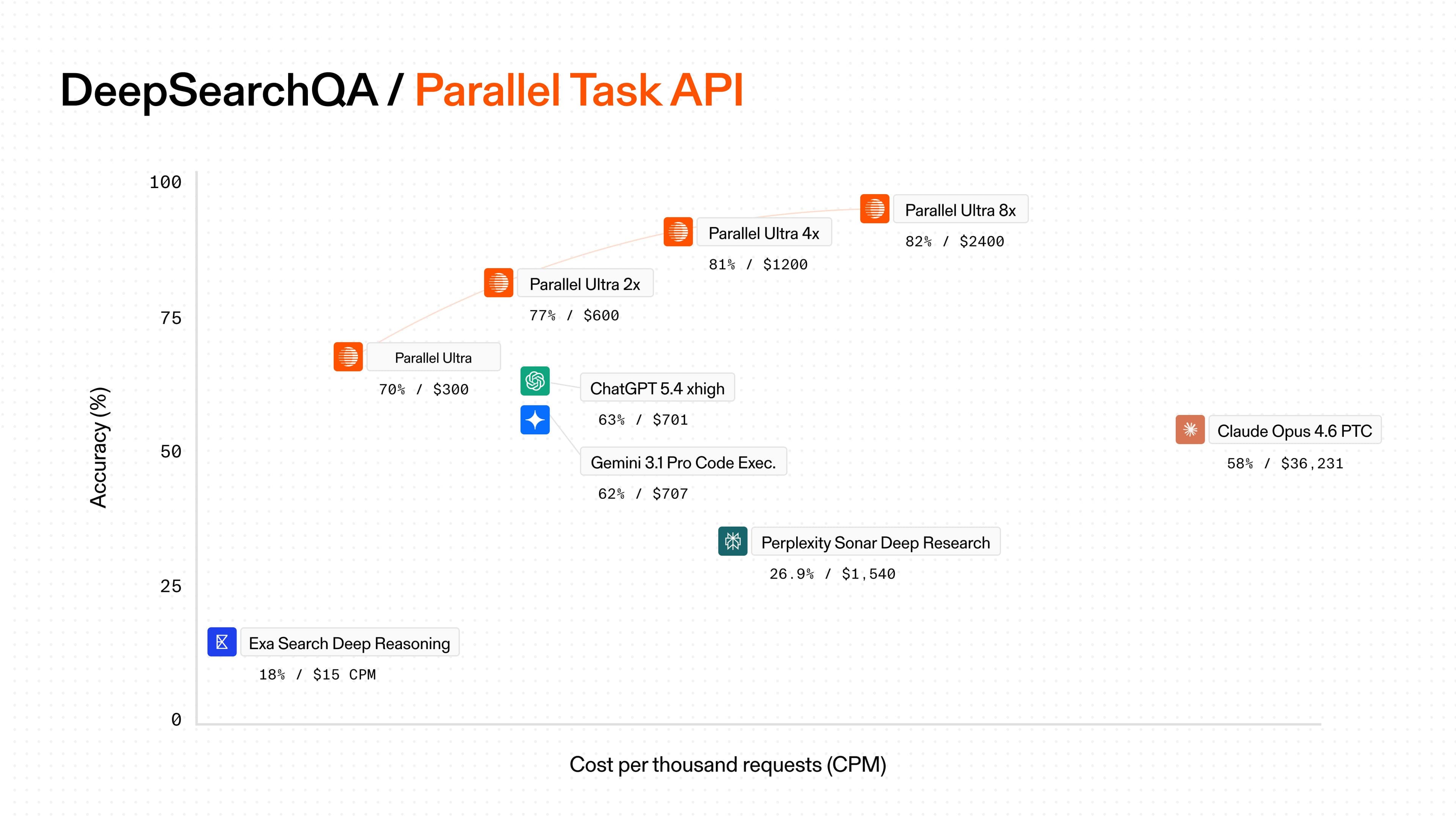
| Provider | Model | Cost (CPM) | Accuracy (%) |
|---|---|---|---|
| Parallel | Ultra 8x | $2400 | 82 |
| Parallel | Ultra 4x | $1200 | 81 |
| Parallel | Ultra 2x | $600 | 77 |
| Parallel | Ultra | $300 | 70 |
| OpenAI | GPT 5.4 with code execution | $701 | 63 |
| Gemini 3.1 Pro with code execution | $707 | 62 | |
| Anthropic | Opus 4-6 with PTC | $36,231* | 58 |
| Perplexity | Sonar Pro | $883 | 28 |
| Exa | Search Deep Reasoning | $15 | 18 |
_CPM: USD per 1,000 requests. Cost is shown on a log scale._
_*The cost of Opus 4-6 is higher than expected due to Anthropic’s potential billing issue, where prompt caching savings for PTC are not passed on to the user._
DeepSearchQA is a 900-question evaluation from Google designed to test agents on multi-step information-seeking tasks across 17 fields of expertise. Each question is a causal chain: you can't answer the second part without resolving the first, and you can't resolve the first without searching the web, reading the results, and reasoning about what to search next.
A typical query might ask: _identify every researcher who co-authored papers with a specific professor at three different institutions over a decade, then determine which of those co-authors later joined a federal advisory committee._ Simple web retrieval won't cut it. The agent needs to plan a research strategy, execute multiple searches, cross-reference results across sources, and synthesize a precise answer with zero false positives.
Here, accuracy on DeepSearchQA means "fully correct": the response must be semantically identical to the ground-truth set. The agent has to find all correct answers while including none that are wrong.
_*We use DeepSearchQA instead of BrowseComp to ensure more reliable evaluation, as some models have begun to memorize portions of the BrowseComp dataset, potentially inflating performance._
Our results stem from combining several techniques.
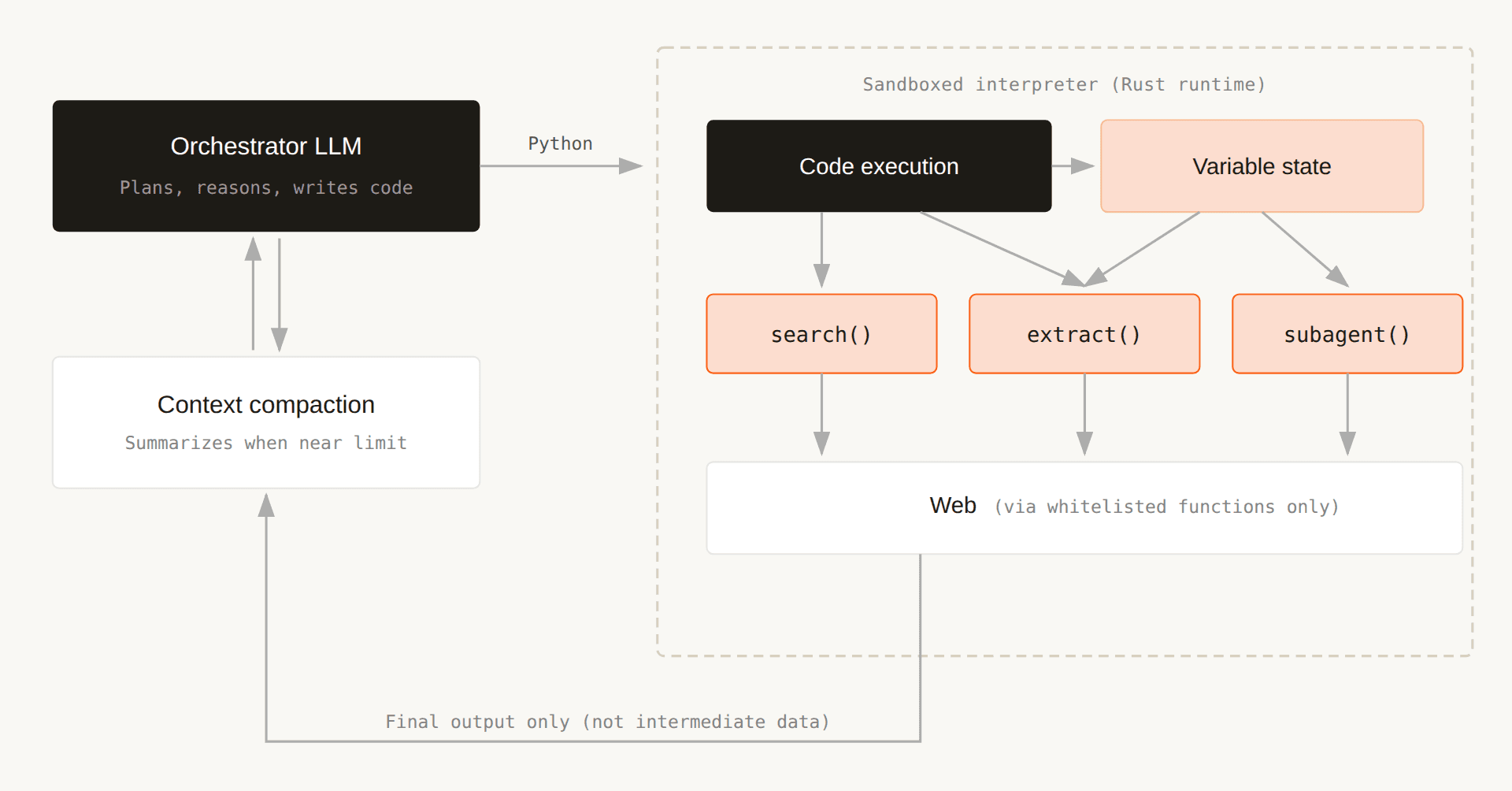
Together, these techniques allow us to scale reasoning depth and reliability while maintaining efficiency, leading to state-of-the-art results on DeepSearchQA. Instead of having the model orchestrate tools through tool calling, we gave it the ability to write and execute code.
The orchestrating model generates Python that calls research tools as ordinary functions. This code runs in a sandboxed interpreter. Only the final output of each code block re-enters the model's context. Intermediate data stays in the interpreter's variable state, not in the conversation history.
12345Step 1: search("company X revenue 2024") → [5 results in context]
Step 2: extract(url_1) → [full page content in context]
Step 3: extract(url_2) → [full page content in context]
Step 4: search("company X revenue 2023") → [5 more results in context]
...context grows with every step``` Step 1: search("company X revenue 2024") → [5 results in context]Step 2: extract(url_1) → [full page content in context]Step 3: extract(url_2) → [full page content in context]Step 4: search("company X revenue 2023") → [5 more results in context]...context grows with every step``` Each step inflates the context window. By step 8, the model spends most of its capacity re-reading old results.
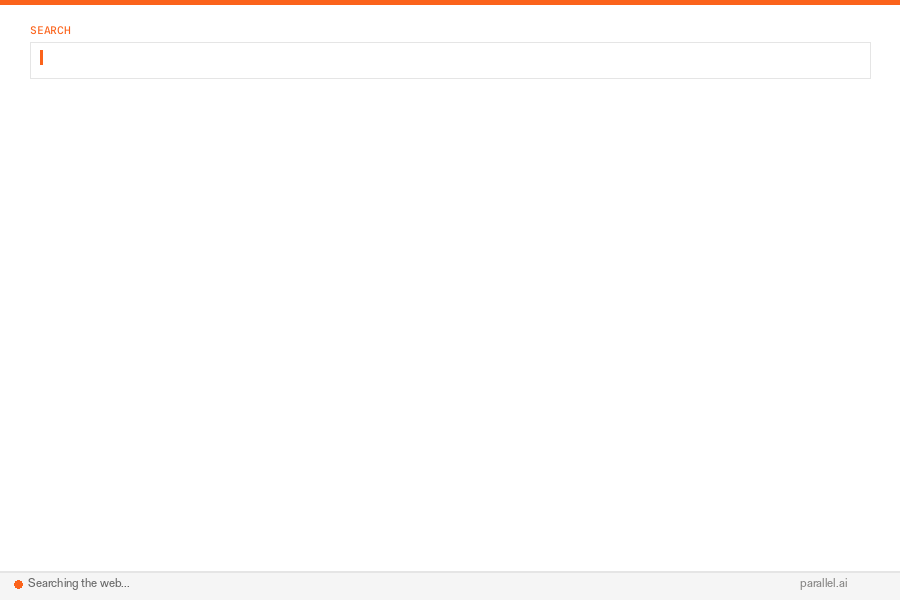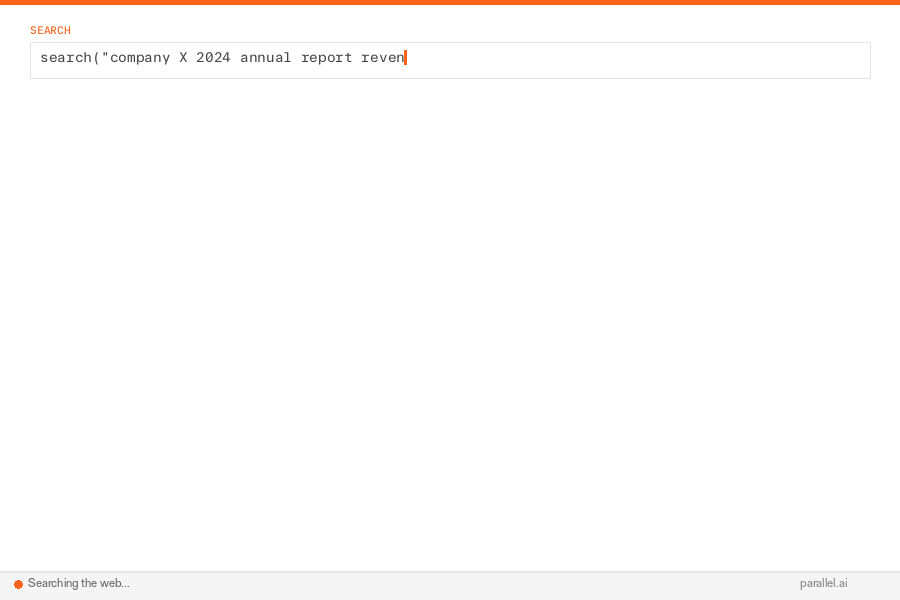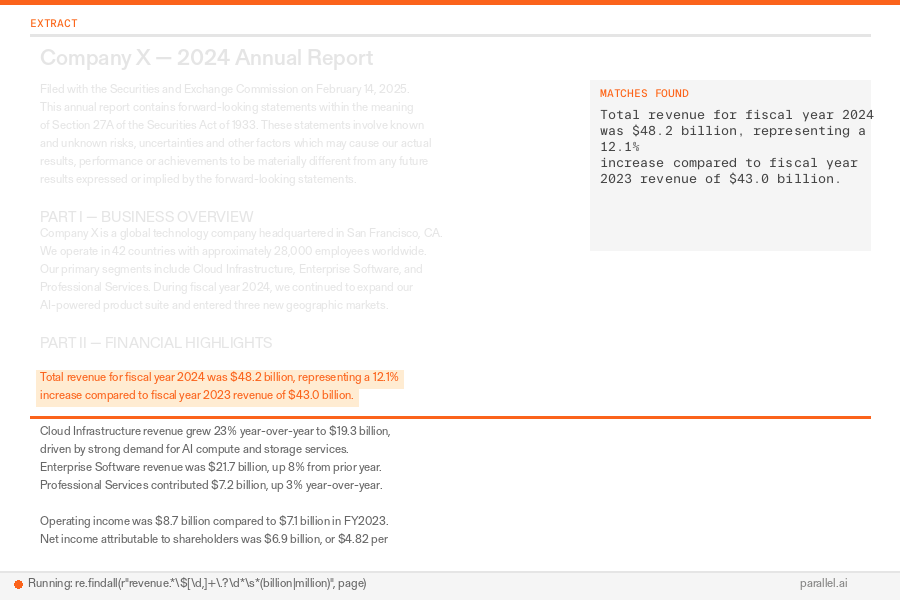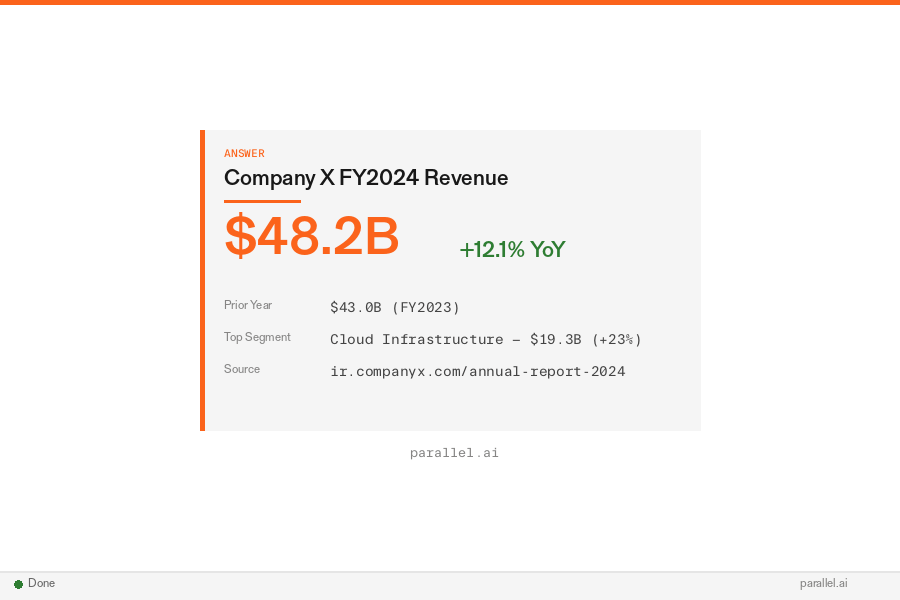
12345678910111213141516171819# First, use one search step to discover the URL pattern.
results_2024 = search("Company X 2024 annual report")
report_2024 = results_2024[0].url
# e.g. https://investors.companyx.com/financials/annual-reports/2024-annual-report.pdf
# Infer a reusable template from the 2024 URL and a parse function parse_fn.
url_template = "https://investors.companyx.com/financials/annual-reports/{year}-annual-report.pdf"
years = [2022, 2023, 2024]
reports = {}
for year in years:
url = url_template.format(year=year)
reports[year] = parse_fn(extract(
question=f"What was Company X's reported revenue in {year}? Return the value and supporting quote.",
urls=[url],
))
return reports``` # First, use one search step to discover the URL pattern.results_2024 = search("Company X 2024 annual report")report_2024 = results_2024[0].url# e.g. https://investors.companyx.com/financials/annual-reports/2024-annual-report.pdf # Infer a reusable template from the 2024 URL and a parse function parse_fn.url_template = "https://investors.companyx.com/financials/annual-reports/{year}-annual-report.pdf" years = [2022, 2023, 2024]reports = {} for year in years: url = url_template.format(year=year) reports[year] = parse_fn(extract( question=f"What was Company X's reported revenue in {year}? Return the value and supporting quote.", urls=[url], )) return reports``` Multiple searches, extractions, and analyses happen in a single execution step. The full page content of both extracted pages (potentially tens of thousands of tokens) never enters the research agent's context. Only the extracted revenue figures flow back.
This compounds. A 20-step research task that would fill a 128K context window under tool calling stays under 30K tokens because intermediate data lives in the interpreter, not the conversation.
Variables created in one code execution step survive to the next. When the model writes _findings["report"] = report_2024_ in iteration 3, that variable is still accessible in iteration 7 when the model needs to cross-reference revenue against employee headcount.
This creates a separation that matters: the conversation history captures the model's high-level reasoning trajectory, while the interpreter's variable state captures the raw data it has gathered. The conversation can be compacted without losing granular data.
Running LLM-generated code in production requires strong isolation. Our interpreter is a sandboxed Python runtime built on Rust with no access to the network, filesystem, or operating system. The only way code interacts with the outside world is through explicitly injected functions: search, extract and a handful of state management utilities.
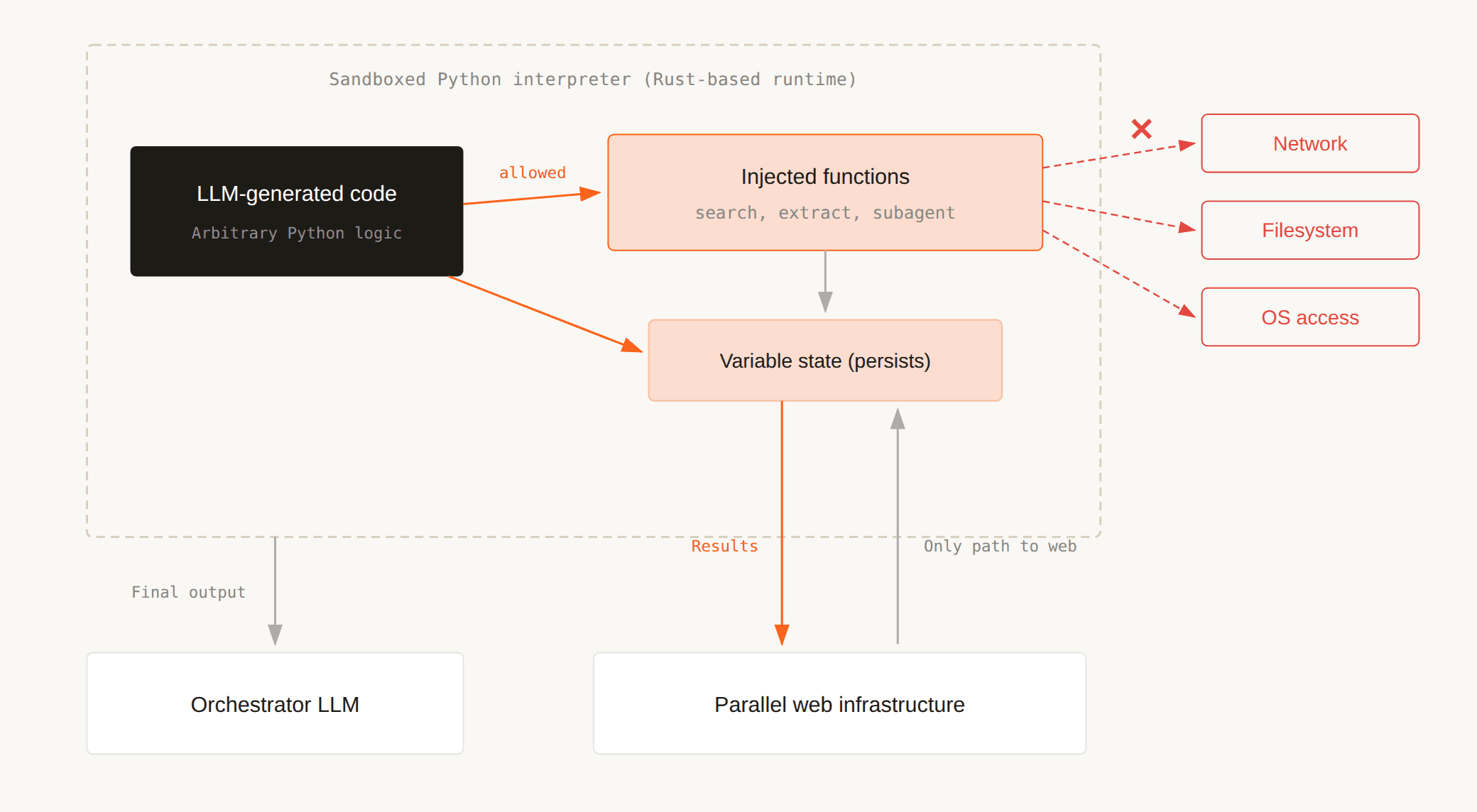
This boundary gives us two things. First, the model can write complex data processing logic (filtering, aggregation, string manipulation, conditional branching) without risk of side effects.
One of the attractive features of Parallel’s Task API is fixed and predictable costs rather than per-token pricing. We have built our agent harness to support budgets as a first-class concept. This budget isn’t just a fixed limit on the number of steps. A fixed step limit penalizes simple and complex queries equally. We track cumulative cost across iterations instead. The system monitors token spend across all LLM calls, both the orchestrating model and any sub-model invocations, and injects budget warnings when remaining spend drops below a threshold. When the budget is nearly exhausted, the model synthesizes its findings and produces a final answer with whatever it has gathered.
A simple factual query might terminate in 2 iterations and cost a few cents. A complex multi-source comparison might run for 15 iterations across a larger budget. The architecture adapts to the difficulty of the question rather than imposing a uniform ceiling. This is also how we offer the full range of Processors from Ultra ($300 CPM) through Ultra8x ($2,400 CPM): higher-tier Processors get a larger budget, which lets the agent pursue more research paths before synthesizing.
Even with code execution keeping intermediate data out of context, long research sessions accumulate history: the model's reasoning, code blocks, and execution summaries. When this history approaches context limits, we trigger compaction, a summarization pass that condenses earlier conversation turns while preserving key findings and the current research trajectory.
The persistent variable state in the interpreter is unaffected by compaction (it lives in the interpreter, not the conversation). This means the model can sustain research across many more iterations than its raw context window would suggest.
Most deep research systems follow a familiar loop: an LLM generates a plan, calls a tool, reads the result, and repeats. This works for simple queries but degrades as research complexity grows. We evaluated several architectural patterns for complex research workflows, each with different trade-offs across context efficiency, granularity of information access, and adaptability.
| Architecture | Cost efficiency | Fine-grained Research Control | Adaptability | Reason |
|---|---|---|---|---|
| Naive Agent Loop (LLM → tool → result → LLM → …) | ❌ | ❌ | ✅ | Maximally flexible, but context grows at every step. The model ends up spending too much capacity re-reading intermediate results. |
| Agent Loop with context compression | ✅ | ❌ | 🟠 | Keeps context manageable, but important details are often compressed away. This makes it harder to revisit evidence or pursue subtle lines of inquiry. |
| Static Plan + sub-agents | ✅ | 🟠 | ❌ | Works well for predictable workflows, but cannot adapt cleanly once the plan is set. |
| Agent Loop with sub-agents | ✅ | 🟠 | 🟠 | Better runtime flexibility than static planning, but still suffers from coordination and memory fragmentation across agents. |
| Task API Harness (Parallel) | ✅ | ✅ | ✅ | Preserves detailed evidence access while keeping the intermediate state out of the model context. It can adapt mid-run, branch when needed, and scale without bloating the prompt. |
1234567891011121314import parallel
client = parallel.Client(api_key="your-api-key")
task = client.task_runs.create(
objective="Identify every researcher who co-authored papers "
"with Dr. Maria Chen at Stanford, MIT, and Caltech "
"between 2010 and 2020, then determine which of those "
"co-authors later joined the NIH Advisory Committee "
"to the Director.",
processor="ultra8x",
)
print(task.output)``` import parallel client = parallel.Client(api_key="your-api-key") task = client.task_runs.create( objective="Identify every researcher who co-authored papers " "with Dr. Maria Chen at Stanford, MIT, and Caltech " "between 2010 and 2020, then determine which of those " "co-authors later joined the NIH Advisory Committee " "to the Director.", processor="ultra8x",) print(task.output)``` The Task API is a general-purpose web research agent API. Define what you need in natural language or structured JSON, and it handles research, synthesis, and structured output with citations and confidence levels. Processors range from Lite (basic lookups, $5/1K) through Ultra8x (the hardest deep research, $2,400/1K).
Parallel builds web infrastructure for AI. Our APIs, including Search, Extract, Task, FindAll, and Monitor, give AI agents structured, grounded access to the open web, powered by a rapidly growing proprietary index of the global internet.
Parallel turns human workflows that took days into agentic workflows that take seconds. Fortune 100s and leading frontier AI companies including Harvey, Manus, Starbridge, and Profound rely on Parallel for legal grounding, fact-checking, contract monitoring, and high-quality content generation.
Get started at platform.parallel.ai[platform.parallel.ai]
Sign up for free. No credit card required.
By Parallel
April 7, 2026