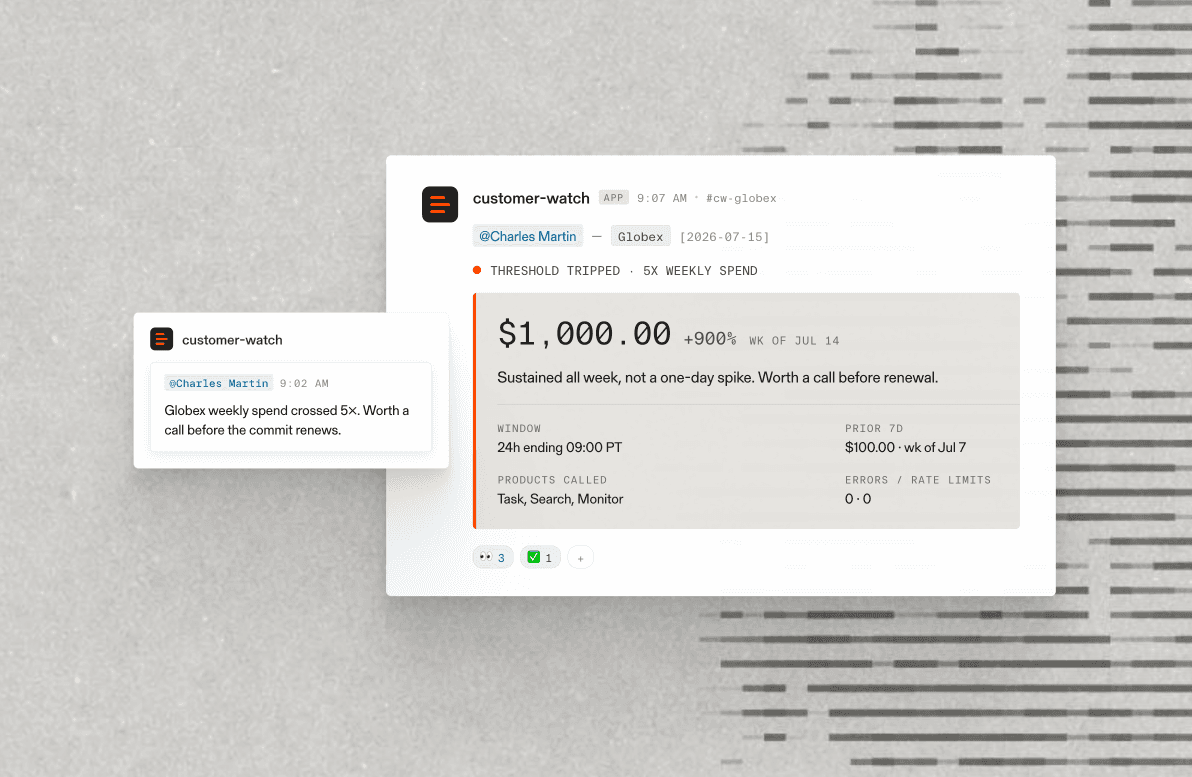
Jul 30, 2026
- [Building an always-on background agent to proactively support customers](https://parallel.ai/blog/customer-watch-background-agent)
Tags:Developers
Author: By Khushi ShelatSeptember 9, 2025
Expanded results that demonstrate Parallel's complete price-performance advantage in Deep Research.

We previously released benchmarks[previously released benchmarks] for Parallel Deep Research that demonstrated superior accuracy and win rates against leading AI models. Today, we're publishing expanded results that showcase our complete price-performance advantage - delivering the highest accuracy across every price point.
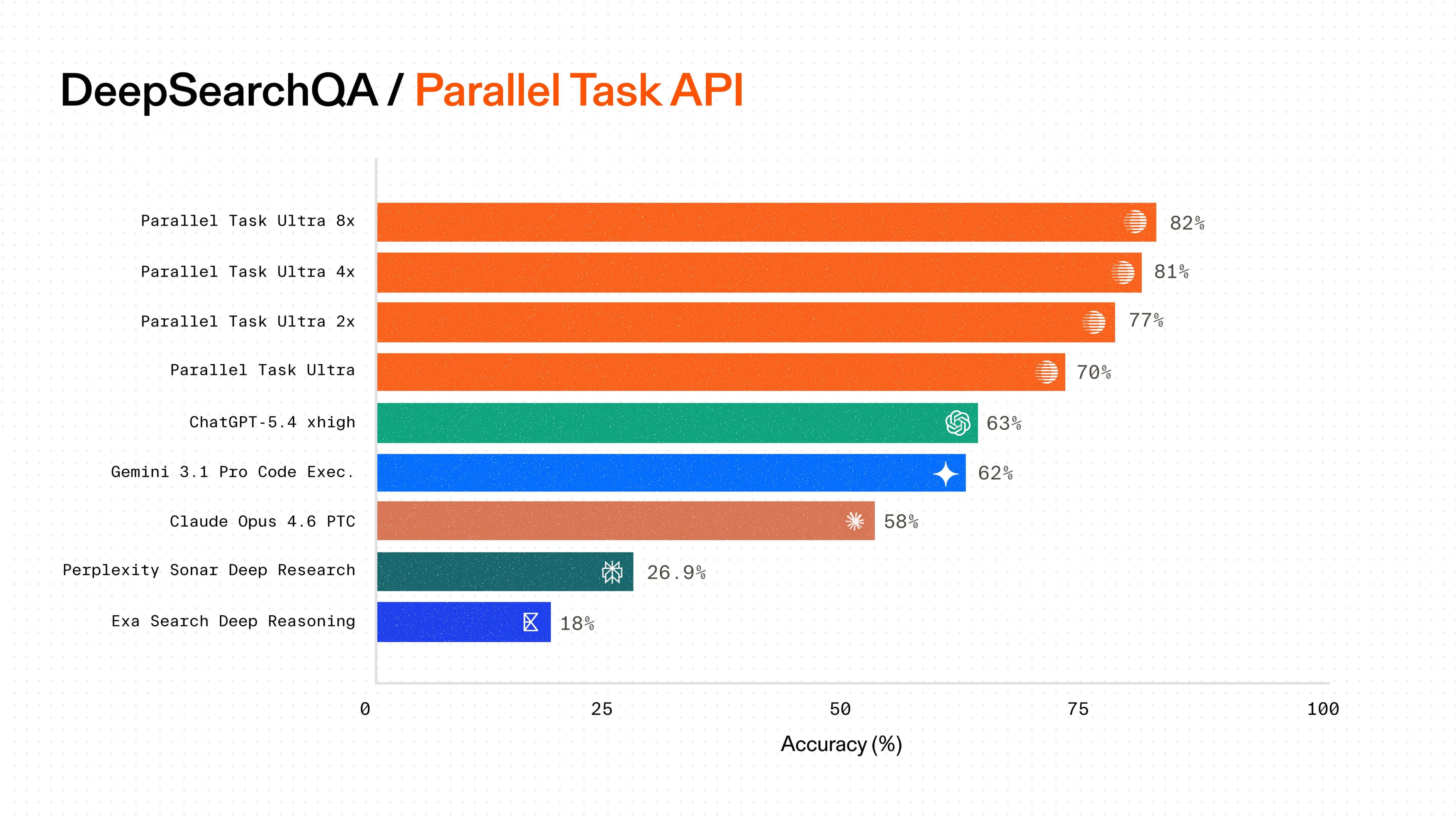
We evaluated Parallel against all available deep research APIs on two industry-standard benchmarks. Our processors consistently deliver the highest accuracy at each price tier.
OpenAI's BrowseComp tests deep research capabilities through 1,266 complex questions requiring multi-hop reasoning, creative search strategies, and synthesis across scattered sources.
Accuracy (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark[benchmark], created by OpenAI, contains 1,266 questions requiring multi-hop reasoning, creative search formulation, and synthesis of contextual clues across time periods. Results are reported on a random sample of 100 questions from this benchmark.
This benchmark[benchmark], created by OpenAI, contains 1,266 questions requiring multi-hop reasoning, creative search formulation, and synthesis of contextual clues across time periods. Results are reported on a random sample of 100 questions from this benchmark.
| Series | Model | Cost (CPM) | Accuracy (%) | | --------- | ---------- | ---------- | ------------- | | Parallel | Pro | 100 | 34 | | Parallel | Ultra | 300 | 45 | | Parallel | Ultra2x | 600 | 51 | | Parallel | Ultra4x | 1200 | 56 | | Parallel | Ultra8x | 2400 | 58 | | Others | GPT-5 | 488 | 38 | | Others | Anthropic | 5194 | 7 | | Others | Exa | 402 | 14 | | Others | Perplexity | 709 | 6 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark[benchmark], created by OpenAI, contains 1,266 questions requiring multi-hop reasoning, creative search formulation, and synthesis of contextual clues across time periods. Results are reported on a random sample of 100 questions from this benchmark.
Our results demonstrate clear price-performance leadership, with our Ultra processor achieving 45% accuracy at $300 CPM at up to 17X lower cost compared to alternatives. Our newly available high-compute processors push accuracy even further for critical research tasks, with Ultra8x reaching 58%.
**DeepResearch Bench**
DeepResearch Bench evaluates the quality of long-form deep research reports across 22 fields including Business & Finance, Science & Technology, and Software Development. The benchmark consists of 100 PhD-level tasks and assesses the multistep web exploration, targeted retrieval, and higher-order synthesis capabilities of deep research agents.
Win Rate vs Reference (%)
COST (CPM)
WIN RATE VS REFERENCE (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark[benchmark] contains 100 expert-level research tasks designed by domain specialists across 22 fields, primarily Science & Technology, Business & Finance, and Software Development. It evaluates AI systems' ability to produce rigorous, long-form research reports on complex topics requiring cross-disciplinary synthesis. Results are reported from the subset of 50 English-language tasks in the benchmark.
This benchmark[benchmark] contains 100 expert-level research tasks designed by domain specialists across 22 fields, primarily Science & Technology, Business & Finance, and Software Development. It evaluates AI systems' ability to produce rigorous, long-form research reports on complex topics requiring cross-disciplinary synthesis. Results are reported from the subset of 50 English-language tasks in the benchmark.
| Series | Model | Cost (CPM) | Win Rate vs Reference (%) | | -------- | ---------- | ---------- | ------------------------- | | Parallel | Ultra | 300 | 82 | | Parallel | Ultra2x | 600 | 86 | | Parallel | Ultra4x | 1200 | 92 | | Parallel | Ultra8x | 2400 | 96 | | Others | GPT-5 | 628 | 66 | | Others | O3 Pro | 4331 | 30 | | Others | O3 | 605 | 26 | | Others | Perplexity | 538 | 6 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
This benchmark[benchmark] contains 100 expert-level research tasks designed by domain specialists across 22 fields, primarily Science & Technology, Business & Finance, and Software Development. It evaluates AI systems' ability to produce rigorous, long-form research reports on complex topics requiring cross-disciplinary synthesis. Results are reported from the subset of 50 English-language tasks in the benchmark.
Parallel Ultra achieves an 82% win rate against reference reports at $300 CPM, compared to GPT-5's 66% win rate at $628 CPM - delivering superior quality at half the cost. Our highest compute processor, Ultra8x, reaches a 96% win rate, representing a significant improvement from our previously published 82% benchmark.
We also measured win rate against GPT-5 directly by comparing the RACE scores of Parallel processors vs GPT-5. The results demonstrate that Ultra8x achieves an 88% win rate against GPT-5.
| Category | Win Rate (%) | | -------- | ------------ | | Ultra8x | 88 | | Ultra4x | 84 | | Ultra2x | 80 | | Ultra | 74 |
These benchmark results translate directly to production value. Parallel Deep Research delivers the same high accuracy in whichever format you need - human-readable reports for strategic analysis or structured JSON for machine consumption and database ingestion.
Every output, regardless of format, includes our comprehensive Basis framework:
This complete verification layer means the accuracy demonstrated in our benchmarks comes with the audibility and transparency required for production workflows where every detail matters.
Our price-performance advantage unlocks new possibilities. At these price points, you can run 1000x the number of queries compared to token-based alternatives - transforming deep research from an occasional tool to core infrastructure.
Consider the possibilities:
Our per-query pricing model ensures complete cost predictability. Unlike token-based systems where a single complex query can unexpectedly consume your budget, every Parallel query costs exactly what you expect. This predictability enables confident scaling - whether you're running 10 queries or 10,000.
Parallel Deep Research is available today through our Task API. Choose the processor that matches your accuracy and budget requirements, from Pro for simpler deep research to Ultra8x for the most demanding deep research tasks.
Get started in our Developer Platform[Developer Platform] or explore our documentation[documentation].
_Benchmark Dates_: Benchmarks were run from Aug 11 to Aug 29.
_DeepResearchBench Evaluation_**: **We evaluated all available DeepResearch API solutions on the 50 English-language tasks in the benchmark, measuring both RACE and FACT scores for generated reports. Given that RACE is a relative scoring metric benchmarked against reference materials, we calculated win-rates by comparing each vendor's performance to the human reference reports included in the dataset. A candidate report achieves a "win" when its RACE score exceeds that of the corresponding human reference report.
_BrowseComp Evaluation_**: **For the BrowseComp benchmark, we tested our processors alongside other APIs on a random 100-question subset of the original 1,266-question dataset. All systems were evaluated using the same standard LLM evaluator with consistent evaluation criteria, comparing agent responses against verified ground truth answers.
_Cost Calculation_: Token-based pricing is normalized to cost per thousand queries (CPM) based on actual usage in benchmarks.
Sign up for free. No credit card required.
By Parallel
September 9, 2025