Jul 30, 2026
- [Building an always-on background agent to proactively support customers](https://parallel.ai/blog/customer-watch-background-agent)
Tags:Developers
Author: By Khushi ShelatNovember 3, 2025
Parallel scores state-of-the-art on SEAL-0 and SEAL-HARD benchmarks, designed to challenge search-augmented LLMs on real-world research queries.

The Parallel Task API achieves state-of-the-art performance on SealQA (Search-Augmented LLM Evaluation, a.k.a SEAL)[SealQA (Search-Augmented LLM Evaluation, a.k.a SEAL)], a benchmark that evaluates web search systems against conflicting, noisy, and ambiguous information.
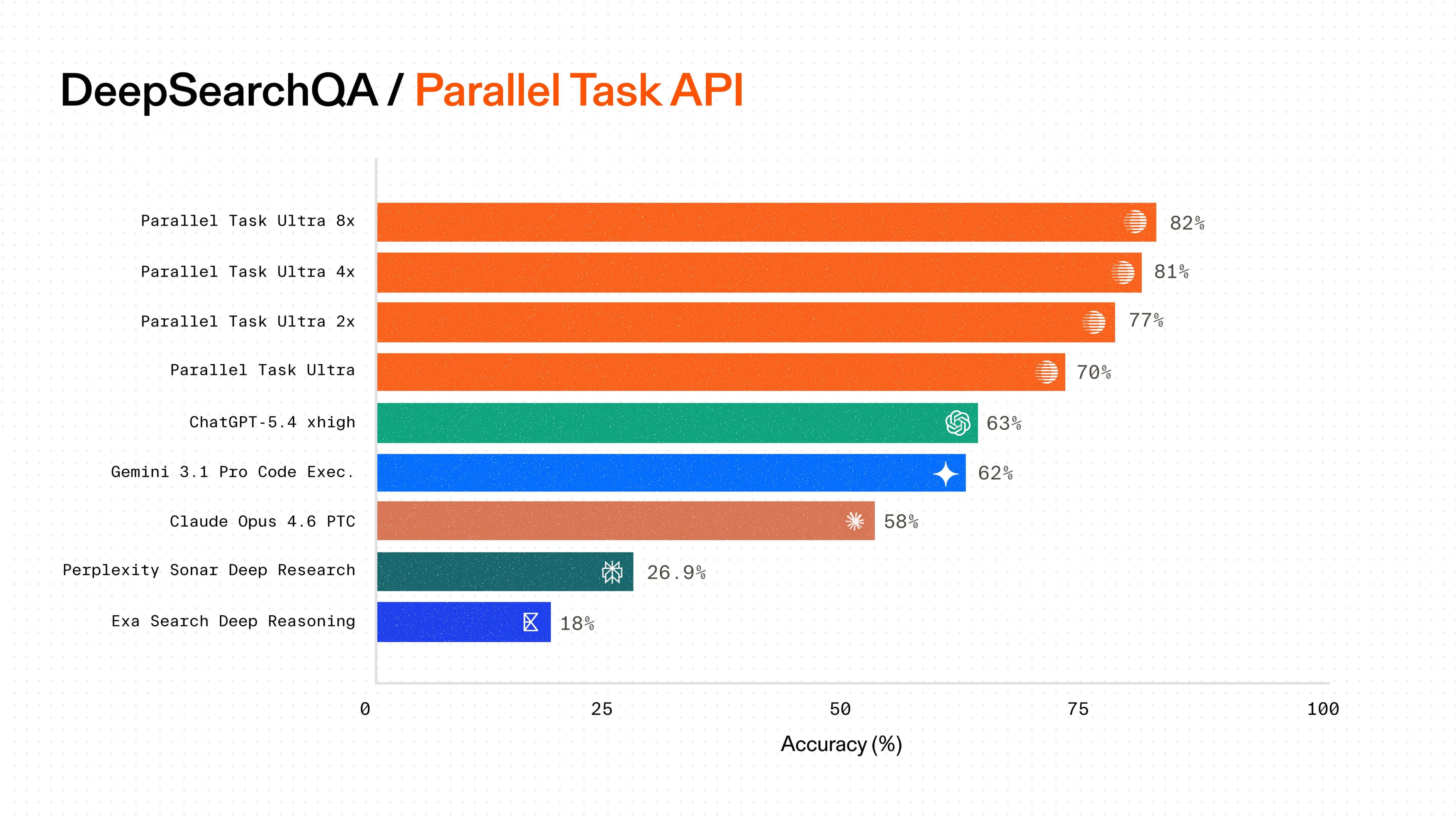
We deliver 42% to 57% accuracy on SEAL-0 and 60% to 70% on SEAL-HARD across our Processor architecture[Processor architecture], measuring price points from $25 to $2400 CPM, establishing the highest accuracy at every price tier.
SEAL represents a fundamentally different class of web research challenge. Previous benchmarks we’ve evaluated, like BrowseComp[BrowseComp], test multi-hop reasoning and persistence in finding obscure facts; SEAL tests whether systems can navigate the inherent contradictions and noise of real web data. SEAL’s questions are intentionally crafted so that search results are ambiguous, conflicting, or noisy, forcing systems to reconcile evidence rather than skim top links.
The benchmark includes two splits: SEAL-0 and SEAL-HARD. Questions generate search results that conflict, contradict, or mislead. SEAL-0 queries are curated through iteration until multiple strong models repeatedly fail, creating a more effective stress test for production web research systems.
These queries demand systems that detect when sources disagree, prioritize credible evidence over noise, and synthesize defensible answers from conflicting information. In the real world, businesses face these same challenges when using agents to perform due diligence, competitive intelligence, and compliance verification, where a single overlooked contradiction can derail critical decisions.
The Parallel Task API Processors outperform commercially available alternatives on both SEAL splits while offering transparent and deterministic per-query pricing.
Accuracy (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
SealQA[SealQA] is a challenge benchmark for evaluating search-augmented language models on fact-seeking questions where web search typically yields conflicting, noisy, or unhelpful results.
SEAL-0 is a core set of problems where even frontier models with browsing consistently fail. It's named "zero" due to its high failure rate.
**Benchmark Details**
We tested on the full SEAL-0 (111 questions) dataset. Questions require reconciling conflicting web sources.
**LLM Evaluator**
We evaluated responses using an LLM-as-a-judge, measuring factual accuracy against verified ground truth.
**Cost Standardization**
Parallel uses deterministic per-query pricing. For token-based APIs, we normalized to cost per thousand queries (CPM) as measured on the benchmark.
**Benchmark Dates**
Testing took place between October 20 and 28, 2025.
SealQA[SealQA] is a challenge benchmark for evaluating search-augmented language models on fact-seeking questions where web search typically yields conflicting, noisy, or unhelpful results.
SEAL-0 is a core set of problems where even frontier models with browsing consistently fail. It's named "zero" due to its high failure rate.
**Benchmark Details**
We tested on the full SEAL-0 (111 questions) dataset. Questions require reconciling conflicting web sources.
**LLM Evaluator**
We evaluated responses using an LLM-as-a-judge, measuring factual accuracy against verified ground truth.
**Cost Standardization**
Parallel uses deterministic per-query pricing. For token-based APIs, we normalized to cost per thousand queries (CPM) as measured on the benchmark.
**Benchmark Dates**
Testing took place between October 20 and 28, 2025.
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ---------------- | ---------- | ------------ | | Parallel | Core | 25 | 42.3 | | Parallel | Core2x | 50 | 49.5 | | Parallel | Pro | 100 | 52.3 | | Parallel | Ultra | 300 | 55.9 | | Parallel | Ultra8x | 2400 | 56.8 | | Others | Perplexity DR | 1258.2 | 38.7 | | Others | Exa Research Pro | 2043.2 | 45 | | Others | GPT-5 | 189 | 48.6 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
SealQA[SealQA] is a challenge benchmark for evaluating search-augmented language models on fact-seeking questions where web search typically yields conflicting, noisy, or unhelpful results.
SEAL-0 is a core set of problems where even frontier models with browsing consistently fail. It's named "zero" due to its high failure rate.
**Benchmark Details**
We tested on the full SEAL-0 (111 questions) dataset. Questions require reconciling conflicting web sources.
**LLM Evaluator**
We evaluated responses using an LLM-as-a-judge, measuring factual accuracy against verified ground truth.
**Cost Standardization**
Parallel uses deterministic per-query pricing. For token-based APIs, we normalized to cost per thousand queries (CPM) as measured on the benchmark.
**Benchmark Dates**
Testing took place between October 20 and 28, 2025.
**On SEAL-0**, Parallel's Ultra8x Processor achieves 56.8% accuracy at $2400 CPM, the highest accuracy among commercially available APIs. At the value tier, our Pro Processor achieves 52.3% accuracy at $100 CPM, compared to 38.7% for Perplexity's deep research at 10x lower cost.
Accuracy (%)
CPM: USD per 1000 requests. Cost is shown on a Log scale.
SEAL-HARD[SEAL-HARD] contains a broader set of queries that includes SEAL-0 and additional highly challenging questions.
**Benchmark Details**
We tested on the full SEAL-0 (111 questions) and SEAL-HARD (254 questions) datasets. Questions require reconciling conflicting web sources.
**LLM Evaluator**
We evaluated responses using an LLM-as-a-judge, measuring factual accuracy against verified ground truth.
**Cost Standardization**
Parallel uses deterministic per-query pricing. For token-based APIs, we normalized to cost per thousand queries (CPM) as measured on the benchmark.
**Benchmark Dates**
Testing took place between October 20 and 28, 2025.
SEAL-HARD[SEAL-HARD] contains a broader set of queries that includes SEAL-0 and additional highly challenging questions.
**Benchmark Details**
We tested on the full SEAL-0 (111 questions) and SEAL-HARD (254 questions) datasets. Questions require reconciling conflicting web sources.
**LLM Evaluator**
We evaluated responses using an LLM-as-a-judge, measuring factual accuracy against verified ground truth.
**Cost Standardization**
Parallel uses deterministic per-query pricing. For token-based APIs, we normalized to cost per thousand queries (CPM) as measured on the benchmark.
**Benchmark Dates**
Testing took place between October 20 and 28, 2025.
| Series | Model | Cost (CPM) | Accuracy (%) | | -------- | ---------------- | ---------- | ------------ | | Parallel | Core | 25 | 60.6 | | Parallel | Core2x | 50 | 65.7 | | Parallel | Pro | 100 | 66.9 | | Parallel | Ultra | 300 | 68.5 | | Parallel | Ultra8x | 2400 | 70.1 | | Others | Perplexity DR | 1221.5 | 50.1 | | Others | Exa Research Pro | 2192.4 | 59.1 | | Others | GPT-5 | 161.7 | 64.6 |
CPM: USD per 1000 requests. Cost is shown on a Log scale.
SEAL-HARD[SEAL-HARD] contains a broader set of queries that includes SEAL-0 and additional highly challenging questions.
**Benchmark Details**
We tested on the full SEAL-0 (111 questions) and SEAL-HARD (254 questions) datasets. Questions require reconciling conflicting web sources.
**LLM Evaluator**
We evaluated responses using an LLM-as-a-judge, measuring factual accuracy against verified ground truth.
**Cost Standardization**
Parallel uses deterministic per-query pricing. For token-based APIs, we normalized to cost per thousand queries (CPM) as measured on the benchmark.
**Benchmark Dates**
Testing took place between October 20 and 28, 2025.
**On SEAL-HARD**, Parallel's Ultra8x Processor achieves 70.1% accuracy at $2400 CPM, the highest accuracy among commercially available APIs. At the value tier, our Pro Processor achieves 66.9% accuracy at $100 CPM, better than Exa Research Pro's accuracy (59.1%) at 20x lower cost.
Parallel’s consistent accuracy gains across Processor tiers demonstrate our leading ability to scale performance with compute budget, flexibility that other systems can't match.
Parallel's infrastructure handles the disagreement and noise inherent in real-world web research through systematic capabilities:
**Conflict detection across sources**: Our systems identify when authoritative sources disagree and surface these conflicts rather than selecting convenient answers.
**Credibility scoring**: We prioritize primary sources, official documentation, and domain authority over secondary reporting and aggregator sites.
**High-fanout research with disciplined pruning**: Systems explore broadly to capture diverse perspectives while managing compute costs through intelligent pruning strategies.
Every response includes comprehensive verification through our Basis framework[Basis framework], which features citations linking to source materials, detailed reasoning for each output field, relevant excerpts from cited sources, and calibrated confidence scores that reflect uncertainty. These features make Parallel Processors production-ready for workflows where defensibility and auditability matter.
Start with the Parallel Task API[Parallel Task API] in our Developer Platform or explore the documentation[documentation].
Sign up for free. No credit card required.
By Parallel
November 3, 2025