Jul 30, 2026
- [Building an always-on background agent to proactively support customers](https://parallel.ai/blog/customer-watch-background-agent)
Tags:Developers
Author: By Khushi ShelatApril 20, 2026
Finch replaced a three-step search-extract-validate pipeline with a single Parallel Task API call, cutting per-query costs by 96% and eliminating the defensive engineering overhead that came with an unreliable vendor.

**Tiered processing** lets Finch match cost and accuracy to query complexity at the individual task level
Finch builds the back office that plaintiff law firms never had. The company pairs an in-house legal team with AI agents to handle the research, case preparation, and administrative work that bogs down attorneys. Lawyers focus on settlements and litigation; Finch handles everything upstream. Their current focus is personal injury pre-litigation, with plans to expand into other plaintiff law areas.
The problem Finch targets is a supply-side bottleneck: 75% of Americans who need legal help can't get it. Law firms hit capacity limits and refer cases out rather than hiring more staff to handle the work.
Finch's AI agents run structured research workflows at scale, pulling case-relevant facts from the web, enriching records, and feeding structured outputs into the firm's data models. Before Parallel, Finch powered these workflows through another search API provider.
That vendor's API contract was unreliable. Fields appeared and disappeared between responses with no warning. Finch's engineers wrote defensive validation layers and permissive schemas to keep production from breaking. The search quality compounded the problem: results came back as free text that required a second extraction pass before the data could enter Finch's structured pipelines. Every query became a three-step chain: search, extract, validate.
The engineering overhead of maintaining defensive wrappers around an inconsistent API consumed time that should have gone toward Finch's core product.
Finch migrated to Parallel's Task API in November and now runs all web research through it. They break these two into two key workflows:
Finch is also exploring Parallel's Monitor API for passive web monitoring as a future addition to their pipeline, so that agents can kick off research themselves, without human intervention.
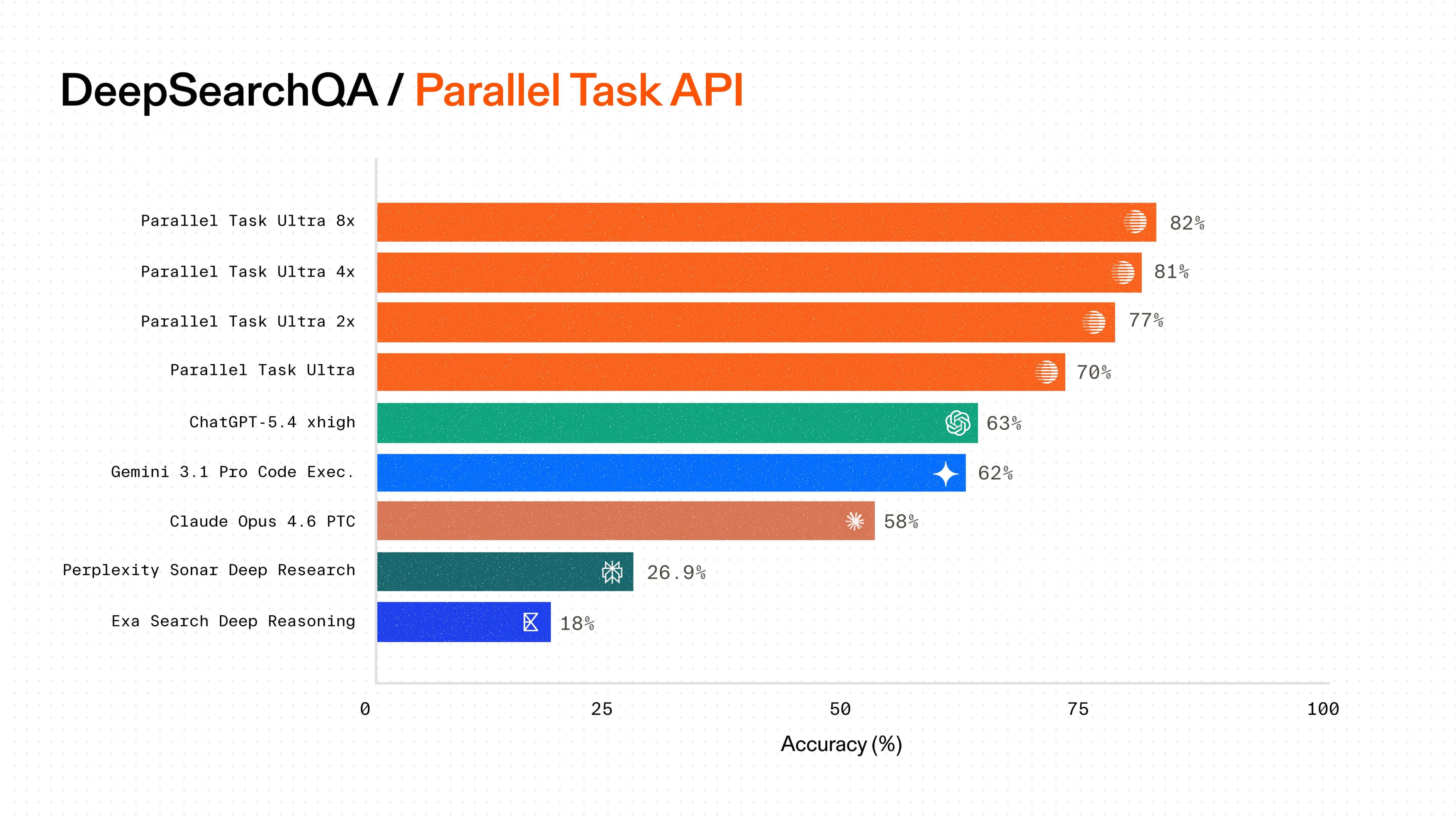
A 90% drop in per-task cost. Finch now runs higher volumes than before at a fraction of the spend.
> **"We went from spending engineering cycles on defensive validation to spending them on product. The Task API gives us structured outputs with citations in a single call, which is exactly what production legal AI needs."**
> **— Ben Weems, CTO, Finch**
After three-plus months in production, Finch has seen zero 5xx errors or timeouts from Parallel. The team that previously built defensive validation layers around an unreliable API now builds product features instead.
Parallel's tiered pricing lets Finch match compute to complexity across their entire operation. Deterministic workflows run on Lite. Production agents use Core. The tradeoffs between speed, accuracy, and cost are explicit at each tier, so Finch's engineers can make informed decisions at the query level rather than paying a flat rate for capabilities they don't always need
Sign up for free. No credit card required.
By Parallel
April 20, 2026