Jul 21, 2026
- [Introducing the Parallel Responses API](https://parallel.ai/blog/responses-api)
Tags:Product
Author: By ParallelMay 5, 2026

We recently shipped parallelmpp.dev[parallelmpp.dev], a gateway that puts Parallel's Search, Extract, and Task APIs behind HTTP 402 Payment Required. An agent can call it without an API key, without a contract, and without a human in the loop. It pays per request in the rail of its choice (Tempo stablecoins, or x402 on Base), gets back the same response shape Parallel customers see today, and moves on.
This is the engineering story behind that launch: why HTTP 402 turned out to be the right contract for autonomous agents, how we run two payment rails on one gateway, and the design choices that fell out of treating the price tag as the only thing the caller has to agree to.
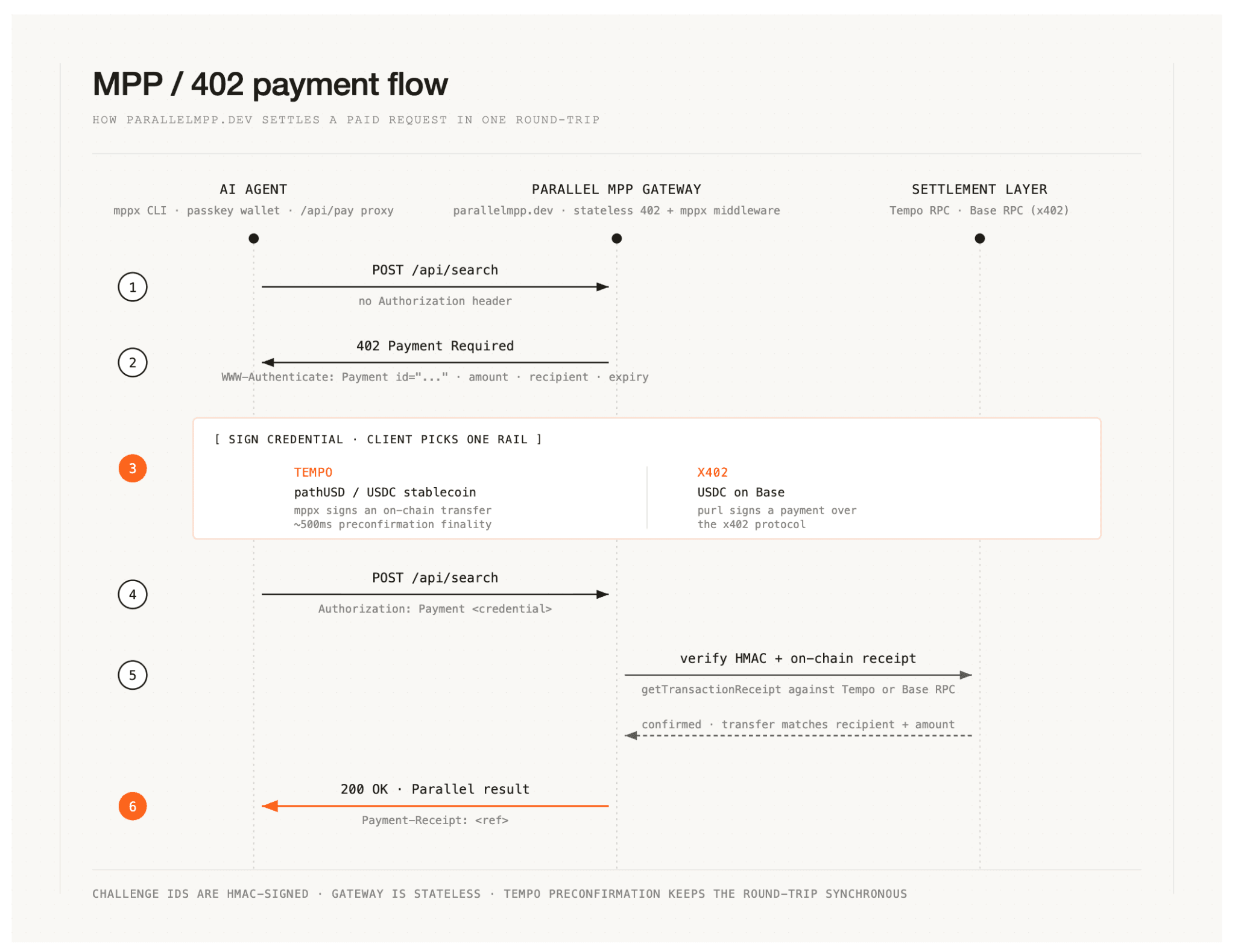
Parallel's APIs are built for agents. The provisioning model around them, on the other hand, was built for humans. To call Search or Task today, you create an account, generate a key, paste it into your environment, and live with the consequences if it leaks. That works fine when a developer is in the loop. It breaks down the moment the caller is itself an agent making a one-off decision: "Should I spend two cents to read this page right now?" Asking that question requires a payment relationship that exists at request time, not at onboarding time.
HTTP 402 is the one status code in the spec that contemplates this. The Machine Payments Protocol (MPP) gives 402 a wire format: a WWW-Authenticate: Payment challenge on the unpaid request, an Authorization: Payment credential on the retry, and an on-chain or Stripe-backed settlement in between. The contract is small enough to fit on one screen and old enough to ride on every HTTP client an agent already uses. We picked it as the substrate for the gateway and started designing inward from there.
The gateway exposes three paid endpoints (POST /api/search at $0.01, POST /api/extract at $0.01 per URL, and POST /api/task at $0.30 ultra or $0.10 pro), plus free routes for discovery, task polling, and wallet balance lookups. The interesting decision was on the payment side: not which rail to support, but how to support more than one without forking the route surface.
We landed on two rails, all routed through the same middleware:
A single middleware instance handles the 402 issuance and credential verification for both of the routes. The route handler doesn't know, or care, which rail the caller used. It sees a 200, a Payment-Receipt header, and a parsed body, and proceeds as if it were any other authenticated request. That separation matters because we can add or retire a rail without touching the routes that call Parallel.
The first design choice we got right early was making 402 challenges stateless. The challenge has an ID field that is an HMAC-SHA256 of the challenge parameters: realm, method, intent, request body, and expiry. When the client retries with a credential referencing that ID, we recompute the HMAC against the parameters in the credential and check the IDs match. We never write the issued challenge anywhere.
This sounds incidental. It isn't. Stateless issuance means the gateway can horizontally scale behind any load balancer, restart cleanly, and survive a database outage without dropping in-flight requests. It also means there is no challenge replay window to manage and no TTL to tune. The expiry travels inside the signed parameters; if a client tries to redeem a credential past it, the math fails, and the request 402s again. The whole challenge layer is a pure function.
Stripe's preview API for crypto PaymentIntents returns a Tempo and Base deposit address. We cache that address in a small in-memory set, return it as the recipient on the 402 challenge, and on retry, confirm the credential references an address from our cache before passing the request to mppx or purl for verification.
12345678910111213141516171819202122232425262728293031async function createPayToAddress(request: Request, amountCents: number): Promise<`0x${string}`> {
const authHeader = request.headers.get('authorization')
if (authHeader && Credential.extractPaymentScheme(authHeader)) {
const credential = Credential.fromRequest(request)
const toAddress = credential.challenge.request.recipient as `0x${string}`
if (!validPayToAddresses.has(toAddress)) {
throw new Error('Invalid payTo address: not found in server cache')
}
return toAddress
}
const paymentIntent = await stripe.paymentIntents.create({
amount: amountCents,
currency: 'usd',
payment_method_types: ['crypto'],
payment_method_data: { type: 'crypto' },
payment_method_options: {
crypto: {
mode: 'deposit',
deposit_options: { networks: ['tempo', 'base'] },
},
},
confirm: true,
return_url: `${baseUrl}/api`,
} as any)
const depositDetails = paymentIntent.next_action.crypto_display_details
const payToAddress = depositDetails.deposit_addresses?.tempo?.address
validPayToAddresses.add(payToAddress)
return payToAddress as `0x${string}`
}``` async function createPayToAddress(request: Request, amountCents: number): Promise<`0x${string}`> { const authHeader = request.headers.get('authorization') if (authHeader && Credential.extractPaymentScheme(authHeader)) { const credential = Credential.fromRequest(request) const toAddress = credential.challenge.request.recipient as `0x${string}` if (!validPayToAddresses.has(toAddress)) { throw new Error('Invalid payTo address: not found in server cache') } return toAddress } const paymentIntent = await stripe.paymentIntents.create({ amount: amountCents, currency: 'usd', payment_method_types: ['crypto'], payment_method_data: { type: 'crypto' }, payment_method_options: { crypto: { mode: 'deposit', deposit_options: { networks: ['tempo', 'base'] }, }, }, confirm: true, return_url: `${baseUrl}/api`, } as any) const depositDetails = paymentIntent.next_action.crypto_display_details const payToAddress = depositDetails.deposit_addresses?.tempo?.address validPayToAddresses.add(payToAddress) return payToAddress as `0x${string}`}``` The cache is leak-tolerant by design. If we lose it during a deploy, the worst case is a few in-flight credentials that 500 instead of 200 because the recipient isn't recognized; the agent retries, gets a fresh challenge, and continues. We leverage Stripe's PaymentIntent record as the durable settlement ledger, not our process memory. We get crypto rails for the on-chain settlement and Stripe for the dashboard, ledger, and reconciliation. That combination took a few iterations to land on, but once we had it, the gateway felt finished.
We wanted POST /api/search to mean the same thing whether it came from a curl with a credential header, the browser with a WebAuthn-signed credential, or an agent calling through the server-side auto-pay proxy. The handler shouldn't care. The contract is the 402 challenge, not the client.
The two modes look like this:
1npx mppx https://parallelmpp.dev/api/search -J '{"query":"AI agent payments 2026"}'``` npx mppx https://parallelmpp.dev/api/search -J '{"query":"AI agent payments 2026"}'``` 1purl https://parallelmpp.dev/api/search -J '{"query":"AI agent payments 2026"}'``` purl https://parallelmpp.dev/api/search -J '{"query":"AI agent payments 2026"}'``` The most agent-native thing we did was make the protocol self-describing. GET /api is free and returns a JSON document with every endpoint, its price, the request body schema, ready-to-paste curl and mppx commands, and a short description of the 402 flow:
1234567891011121314151617{
"description": "Parallel API gateway with single payment rail: MPP/Tempo (pathUSD)",
"endpoints": {
"POST /api/search": { "price": "$0.01", "body": "objective + search_queries, or query" },
"POST /api/extract": { "price": "$0.01/url", "body": { "urls": "string[]", "objective": "string?" } },
"POST /api/task": { "price": "$0.30 (ultra) / $0.10 (pro)", "body": "input + processor" }
},
"agent_integration": {
"mppx_setup": ["npx mppx account create"],
"mppx_usage": [
"npx mppx https://parallelmpp.dev/api/search -J '{\"query\":\"AI funding 2026\"}'",
"npx mppx https://parallelmpp.dev/api/extract -J '{\"urls\":[\"https://example.com\"]}'",
"npx mppx https://parallelmpp.dev/api/task -J '{\"input\":\"HVAC market\",\"processor\":\"ultra\"}'"
]
}
}``` { "description": "Parallel API gateway with single payment rail: MPP/Tempo (pathUSD)", "endpoints": { "POST /api/search": { "price": "$0.01", "body": "objective + search_queries, or query" }, "POST /api/extract": { "price": "$0.01/url", "body": { "urls": "string[]", "objective": "string?" } }, "POST /api/task": { "price": "$0.30 (ultra) / $0.10 (pro)", "body": "input + processor" } }, "agent_integration": { "mppx_setup": ["npx mppx account create"], "mppx_usage": [ "npx mppx https://parallelmpp.dev/api/search -J '{\"query\":\"AI funding 2026\"}'", "npx mppx https://parallelmpp.dev/api/extract -J '{\"urls\":[\"https://example.com\"]}'", "npx mppx https://parallelmpp.dev/api/task -J '{\"input\":\"HVAC market\",\"processor\":\"ultra\"}'" ] }} ``` Pricing constants live in a single api-config.ts module that feeds the middleware, the route handlers, the discovery JSON, and the UI. When we change a price, the document an agent reads at runtime updates in lockstep with what the middleware will charge. There is no version of the truth that disagrees with another version of the truth.
The launch ships with a Claude skill that drops a SKILL.md file into a project's .claude/skills/parallel-mpp/ directory and tells Claude Code to prefer the gateway's Search and Extract endpoints over its built-in web tools. Once the skill is in place, Claude reads GET /api to discover the schema, calls npx mppx to handle the 402 round-trip, and feeds the structured Parallel response back into its reasoning. We tested it against Claude's native search on the same prompts and saw the kind of difference you'd expect: more grounded citations, fewer dropped facts, and an audit trail that shows up in explore.tempo.xyz next to the Stripe Dashboard. Other agent runtimes (Codex, custom MCP servers, anything that can shell out) can use the same setup.
Two things on the list. First, **per-agent budget headers**: a way for a caller to advertise its remaining spend on the request, so an agent that hits a budget gate gets a structured 403 instead of a 200 it can't afford. Second, **streamed 402 challenges for long Task runs**: today, the gateway charges at submission and lets the run play out, but a more honest model is per-step billing for ultra-tier deep research. Both are protocol-level rather than gateway-level, and we're tracking them with the MPP working group.
If you want to see the gateway in action, the docs page at docs.parallel.ai/integrations/agentic-payments[docs.parallel.ai/integrations/agentic-payments] has the full setup, the Claude skill, and ready-to-run mppx commands. The fastest first call is one line:
1npx mppx https://parallelmpp.dev/api/search -J '{"query":"agentic payments 2026"}'``` npx mppx https://parallelmpp.dev/api/search -J '{"query":"agentic payments 2026"}'``` It will return a 402, sign the challenge, retry, and hand back a Parallel search result. That round-trip is the whole product.
Sign up for free. No credit card required.
By Son Do
May 5, 2026