
- [OpenAI web search vs. Parallel vs. Exa vs. Tavily: how to choose](https://parallel.ai/articles/openai-web-search-vs-parallel-vs-exa-vs-tavily-how-to-choose)
Tags:Comparison
Reading time: 12 minApril 1, 2026
When you search for "Italian food" and get results about "Tuscan cuisine," you're experiencing semantic search— an AI-powered technique that understands meaning and intent instead of just matching keywords. Traditional search engines work like ctrl+F across the web, looking for your exact words, while semantic search interprets what you're actually trying to find. This article explains how semantic search works, why it matters for AI systems, and how to implement it in your applications.
Semantic search is an AI-powered search technique that understands the meaning and intent behind your query instead of just matching keywords. When you search for "Italian food," a semantic search system knows you're also interested in "Tuscan cuisine" or "Mediterranean restaurants"—even though you didn't type those exact words.
Traditional search engines work like a ctrl+F function across the entire web. They look for pages containing your exact search terms. Semantic search goes further by analyzing relationships between words, understanding context, and interpreting what you're actually trying to find.
The difference shows up immediately in your results. A keyword search for "best laptops for students" only returns pages with those specific words. A semantic search understands you're looking for affordable, portable computers suitable for academic work—so it might surface results about "top notebooks for college" or "budget-friendly devices for education."
Semantic search combines several AI technologies working together from the moment you hit enter on a query.
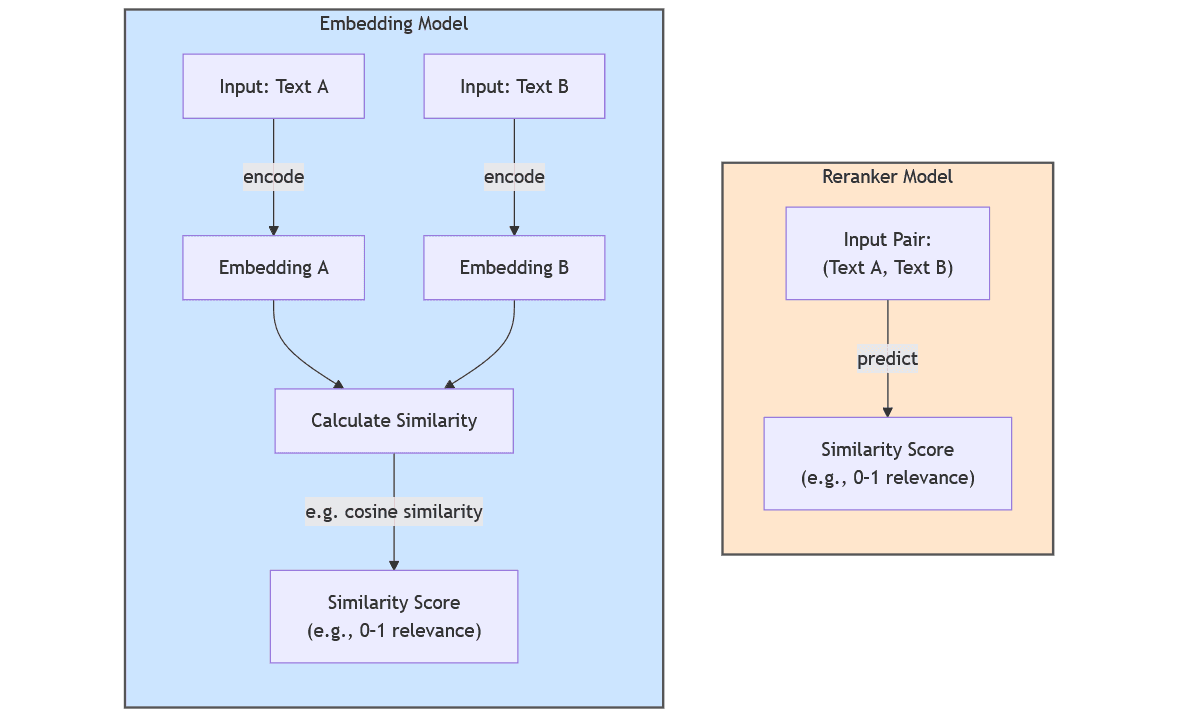
First, the system converts your search query into a mathematical representation called a _vector embedding_. Think of this as translating your words into coordinates in a high-dimensional space where similar meanings cluster together. "Happy," "joyful," and "delighted" sit close to each other in this space, while "sad" lives far away.
At the same time, the search engine has already processed millions of documents and web pages into the same vector format. When your query arrives, the system compares your query vector against its document vectors to find the closest semantic matches—not just keyword matches.
The system analyzes what you're actually looking for beyond the literal words you typed. A query like "best laptop for creative work" gets encoded with context about professional use, performance requirements, and software compatibility. The AI recognizes you're not just looking for the word "best" next to "laptop"—you're looking for recommendations tailored to creative professionals.
Before you ever search, the system has already converted web pages and documents into searchable vector representations. Content about "affordable smartphones" and "budget-friendly mobile devices" ends up near each other in vector space because they mean the same thing. When your query vector arrives, the search engine calculates which document vectors sit closest to it mathematically.
The system considers where you are, what you've searched before, what device you're using, and even what time it is. If you search for "pizza" at 7 PM on your phone, semantic search knows you probably want nearby restaurants—not recipes or the history of Italian cuisine.
After retrieving potentially relevant documents, a large language model (LLM) evaluates which ones best answer your specific question. Some semantic search systems then synthesize information across multiple sources to generate a direct answer rather than just showing you links.
The table below shows how keyword and semantic search differ in practice:
| Feature | Keyword Search | Semantic Search |
|---|---|---|
| Primary function | Matches keywords literally | Interprets intent and meaning behind queries |
| Approach | Lexical matching | Contextual and relational understanding |
| Example | "best laptops for students" only shows pages with those exact words | "best laptops for students" returns "top notebooks for graphic design majors" because it understands contextual similarity |
| Handling synonyms | Requires exact terms or manually added synonyms | Automatically recognizes semantic relationships |
| Query flexibility | Users adapt language to match expected keywords | Users ask questions naturally |
Keyword search excels when you know exactly what you're looking for—a specific product code, a person's name, or an exact phrase. Semantic search shines when you're exploring a topic, asking questions, or don't know the precise terminology.
Several technical components work together to power semantic search systems.
Vector embeddings are numerical representations that encode meaning into hundreds or thousands of dimensions. Words with similar meanings end up close together in this mathematical space. The embedding for "car" sits near "automobile" and "vehicle," while "bicycle" is nearby but not identical, and "airplane" is further away.
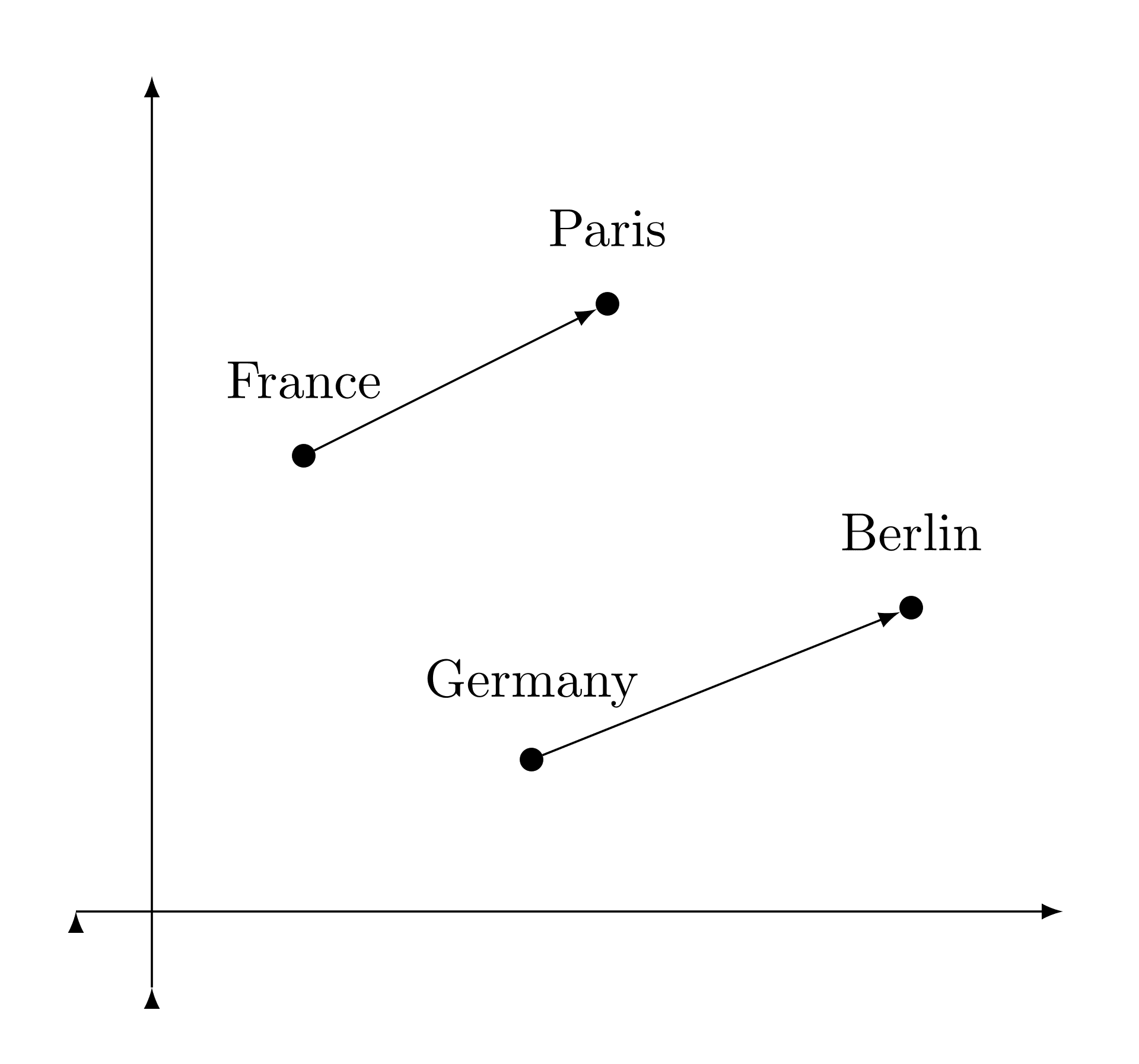
Modern embedding models can capture nuanced relationships. They know that "Paris" relates to "France" in the same way "Tokyo" relates to "Japan"—a geographic relationship encoded mathematically.
Many semantic search systems incorporate _knowledge graphs_, which are structured databases mapping relationships between entities. When you search for "Tesla," a knowledge graph helps the system figure out whether you mean the car company, the inventor Nikola Tesla, or the unit of magnetic flux density.
Knowledge graphs connect entities with explicit relationships: "Elon Musk" founded "Tesla," which produces "electric vehicles," which compete with "traditional automakers." This structured knowledge enhances the semantic understanding that embeddings provide.
After initial retrieval, transformer-based neural networks rerank results by analyzing how well each document actually answers your query. Transformers can consider word order, sentence structure, and contextual nuances that simpler matching algorithms miss. A document might contain all your query terms but still rank low if a transformer determines it doesn't actually address your question.
Semantic search systems learn from user behavior over time. When people click certain results, spend time reading them, and don't reformulate their queries, the system learns those results were relevant. When users immediately hit back and try a different query, the system learns the results missed the mark.
AI agents face a fundamental mismatch with traditional search. They process information as tokens—numerical representations of text—not as web pages designed for human eyes. Traditional search engines return snippet previews and blue links optimized for human clicking behavior, not the dense, information-rich passages that AI agents need for reasoning.
When an AI agent uses traditional search, it has to scrape full web pages, parse HTML, extract relevant content, and summarize everything down to fit in its context window. This multi-step process adds latency, costs tokens, and introduces failure points at every stage.
Semantic search designed for AI agents collapses this entire pipeline. Instead of snippet previews, it returns extended passages optimized for LLM consumption. Instead of forcing agents to guess which links to follow, it delivers ranked, relevant content ready to slot directly into a context window.
For complex reasoning tasks, semantic search enables AI agents to synthesize information across different domains and time periods. An agent researching competitive intelligence can search for "enterprise AI adoption trends," "competitor pricing changes," and "recent funding announcements"—conceptually related queries that would require completely different keyword formulations in traditional search.
The biggest advantage is reduced hallucination. When semantic search returns verifiable information with transparent attribution to source documents, AI agents can ground their outputs in evidence rather than generating plausible-sounding fabrications.
Different industries use semantic search to solve specific information retrieval problems.
In e-commerce, semantic product search helps shoppers find items through natural descriptions. Someone searching for "waterproof hiking boots for wide feet" gets relevant results even when product listings say "water-resistant trail footwear with spacious toe box." The system recognizes the semantic relationship between different phrasings.
Enterprise knowledge management systems let employees search internal documentation using conversational queries. Instead of guessing exact keywords in a policy document, they ask "What's our remote work policy for international contractors?" and semantic search surfaces relevant sections across multiple documents.
Healthcare researchers use semantic search to discover relevant studies across millions of publications. A search for "immune response to mRNA vaccines" returns papers discussing "adaptive immunity following nucleoside-modified RNA immunization"—semantically related research that keyword search would completely miss.
Financial analysts extract insights from earnings reports and regulatory filings using semantic queries. Searching for "supply chain disruption impact" surfaces relevant passages even when documents use terms like "logistics challenges," "procurement delays," or "inventory constraints."
Implementing semantic search for AI applications involves several technical steps.
Start by gathering the documents, web pages, or data sources you want to make searchable. Remove duplicates, fix formatting issues, and filter out low-quality content. Your semantic search system will only be as accurate as the data you index.
Choose an embedding model based on your domain and performance requirements. General-purpose models like OpenAI's text-embedding-3 work well for broad applications. Specialized models trained on medical, legal, or technical text perform better in those specific domains.
Process your documents through the embedding model to generate vector representations, then store them in a vector database like Pinecone, Weaviate, or Qdrant. Include metadata—publication dates, source URLs, document types—to enable filtering and attribution later.
Test your semantic search system against real queries from your use case. Measure whether top results are actually useful, whether the system finds all relevant documents, and how fast results return. Iterate based on measurement, not intuition.
Optimize your system by experimenting with smaller embedding models, adjusting the number of results retrieved, or implementing caching for common queries. Balance accuracy against the computational costs of running inference on every search.
No—semantic search complements structured queries but doesn't replace database operations for transactional data. Use SQL when you know exactly what you're looking for in structured tables. Use semantic search when exploring unstructured text or when you don't know the precise query parameters.
Yes, semantic search works entirely within private environments without external data sharing. You can deploy vector databases and embedding models on your own infrastructure, keeping all data and queries internal.
Multilingual embedding models like mBERT or XLM-RoBERTa show strong performance across languages with limited training data. Cross-lingual transfer learning—training on high-resource languages then fine-tuning on low-resource ones—also yields good results.
Index size depends on your use case scope. A customer support system might index thousands of help articles, while a research tool could index millions of papers. Smaller focused indexes often outperform massive general ones because they contain less noise.
By Parallel
April 1, 2026






